
티스토리 뷰
GNN을 공부하면 GCN, Graph SAGE, GAT(Graph attention)의 이야기를 안들어 볼 수 없다.
이 셋중 DGL 라이브러리의 SAGEConv 레이어가 어떻게 작동하는지 간단한 예제를 통해 공부한 것을 설명해보고자 한다.
예제는 SAGEConv 코드를 보면 제공해주는 코드를 사용하고자 한다.
그 전에 간단하게 GNN에 대해 설명해보고자 한다.
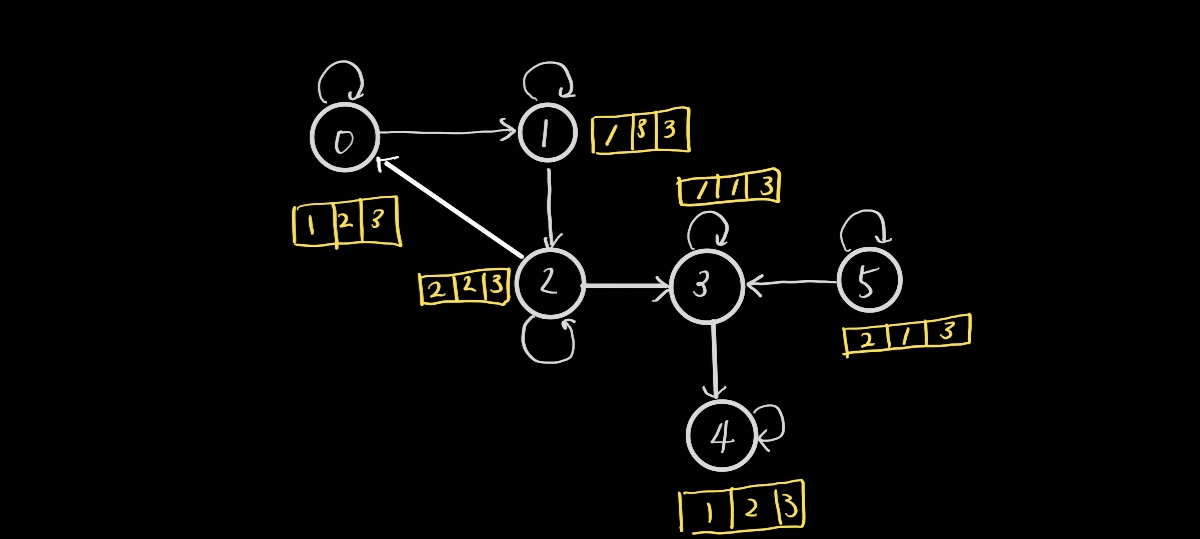
실생활에서 그래프를 그린다고 한다면, 위와 같이 그릴 수 있을 것이다.
GNN은 그래프에 feature를 추가하고, 주어진 feature 사용해 모델을 생성하여 문제를 푼다.
위 그림에는 6개의 Node, Edge, Feature을 그림으로 그려놓았다.
밑에 SAGEConv에서 주는 간단 코드를 봐보자.
import dgl
import numpy as np
import torch as th
from dgl.nn import SAGEConv
# Case 1: Homogeneous graph
g = dgl.graph(([0,1,2,3,2,5], [1,2,3,4,0,3])) #(u,v)
print("========방향성이 있는 그래프==========")
print(g)
g = dgl.add_self_loop(g) # 자기 자신에게 가는 edge를 추가 (즉, (0,0),(1,1)... 추가)
print(g)
print("=====각 노드를 표현하는 vector값=====")
print(g.edges())
feat = th.tensor([
[1,2,3],
[1,3,3],
[2,2,3],
[1,1,3],
[1,2,3],
[2,1,3]
],dtype=th.float32)
print(feat)
print("=======SAGEConv=======")
conv = SAGEConv(3, 2, 'pool') # in_feats / out_featsres = conv(g, feat)
res = conv(g, feat)
res제공하는 코드와 다른 부분은 feature 값이 바뀌는 것을 볼 수 있도록, feat의 값을 바꾸어 주었다.(+ 히든 노드의 수도 바꿔줌 10>3)
눈치 채신분들도 계시겠지만, 위 그래프 그림은 밑에 소스 코드를 보고 그린것이다.
코드를 잠깐 보자면,
DGL라이브러리로 graph를 하나 그린다.
graph를 그리는 방식으론, 가장 대중적인 matrix방식이 있지만, matrix는 저장공간을 많이 차지하기 때문에,
dgl에서는 (u,v)형식으로 간선을 표시하여 graph를 그린다.
그리고 각 node마다의 특징을 feat이란 것에 인위적으로 만들어 주었다.
여기까지 가장 SAGEConv를 보기 전 가장 기본적으로 갖춰야 하는 graph와 feature를 만들었다.
그럼 이제 이 글의 주제인 SAGEConv layer 코드를 한번 보고, 어떻게 작동하는지 설명해보겠다.
일단 SAGEConv layer를 선언부터 봐보자.
SAGEConv(3, 2, 'pool')이 시작될때, 밑에 적어놓은 코드 (__init__)을 수행하게 된다.
class SAGEConv(nn.Module):
def __init__(self,
in_feats, # 3
out_feats, # 2
aggregator_type, # "pool"
feat_drop=0.,
bias=True,
norm=None,
activation=None):
super(SAGEConv, self).__init__()
valid_aggre_types = {'mean', 'gcn', 'pool', 'lstm'}
if aggregator_type not in valid_aggre_types:
raise DGLError(
'Invalid aggregator_type. Must be one of {}. '
'But got {!r} instead.'.format(valid_aggre_types, aggregator_type)
)
self._in_src_feats, self._in_dst_feats = expand_as_pair(in_feats) # 3 3
self._out_feats = out_feats # 2
self._aggre_type = aggregator_type # "pool"
self.norm = norm
self.feat_drop = nn.Dropout(feat_drop) # 0
self.activation = activation # none
if aggregator_type == 'pool':
# node feature를 학습 가능한 layer에서 한번 처리(3 > 3 형태변환 x)
self.fc_pool = nn.Linear(self._in_src_feats, self._in_src_feats)
if aggregator_type == 'lstm':
self.lstm = nn.LSTM(self._in_src_feats, self._in_src_feats, batch_first=True)
if aggregator_type != 'gcn':
# 자기 자신 노드 feature 처리
self.fc_self = nn.Linear(self._in_dst_feats, out_feats, bias=False)
# 이웃 노드 feature 처리
self.fc_neigh = nn.Linear(self._in_src_feats, out_feats, bias=False)
if bias:
self.bias = nn.parameter.Parameter(torch.zeros(self._out_feats))
else:
self.register_buffer('bias', None)
self.reset_parameters()SAGEConv 레이어 선언에서 어려운 부분은 딱히 없다. 굳히 꼽자면, aggregator 함수를 어떤것을 사용하느냐에 따라 처리 방식이 조금 바뀐다는 점만 주의하자.
이제 SAGEConv의 forward함수에서 어떻게 계산이 이루어 지는지 확인해보자. 여기서는 예제에서 제공하듯, "pool" 기법을 사용해본다.
SAGEConv forward의 코드는 밑에와 같다.
def forward(self, graph, feat, edge_weight=None):
self._compatibility_check()
with graph.local_scope():
if isinstance(feat, tuple):
feat_src = self.feat_drop(feat[0])
feat_dst = self.feat_drop(feat[1])
else:
feat_src = feat_dst = self.feat_drop(feat)
if graph.is_block:
feat_dst = feat_src[:graph.number_of_dst_nodes()]
msg_fn = fn.copy_src('h', 'm')
if edge_weight is not None:
assert edge_weight.shape[0] == graph.number_of_edges()
graph.edata['_edge_weight'] = edge_weight
msg_fn = fn.u_mul_e('h', '_edge_weight', 'm')
h_self = feat_dst
# Handle the case of graphs without edges
if graph.number_of_edges() == 0:
graph.dstdata['neigh'] = torch.zeros(
feat_dst.shape[0], self._in_src_feats).to(feat_dst)
# Determine whether to apply linear transformation before message passing A(XW)
lin_before_mp = self._in_src_feats > self._out_feats
# Message Passing
if self._aggre_type == 'mean':
graph.srcdata['h'] = self.fc_neigh(feat_src) if lin_before_mp else feat_src
graph.update_all(msg_fn, fn.mean('m', 'neigh'))
h_neigh = graph.dstdata['neigh']
if not lin_before_mp:
h_neigh = self.fc_neigh(h_neigh)
elif self._aggre_type == 'gcn':
check_eq_shape(feat)
graph.srcdata['h'] = self.fc_neigh(feat_src) if lin_before_mp else feat_src
if isinstance(feat, tuple): # heterogeneous
graph.dstdata['h'] = self.fc_neigh(feat_dst) if lin_before_mp else feat_dst
else:
if graph.is_block:
graph.dstdata['h'] = graph.srcdata['h'][:graph.num_dst_nodes()]
else:
graph.dstdata['h'] = graph.srcdata['h']
graph.update_all(msg_fn, fn.sum('m', 'neigh'))
# divide in_degrees
degs = graph.in_degrees().to(feat_dst)
h_neigh = (graph.dstdata['neigh'] + graph.dstdata['h']) / (degs.unsqueeze(-1) + 1)
if not lin_before_mp:
h_neigh = self.fc_neigh(h_neigh)
elif self._aggre_type == 'pool':
graph.srcdata['h'] = F.relu(self.fc_pool(feat_src))
graph.update_all(msg_fn, fn.max('m', 'neigh'))
h_neigh = self.fc_neigh(graph.dstdata['neigh'])
elif self._aggre_type == 'lstm':
graph.srcdata['h'] = feat_src
graph.update_all(msg_fn, self._lstm_reducer)
h_neigh = self.fc_neigh(graph.dstdata['neigh'])
else:
raise KeyError('Aggregator type {} not recognized.'.format(self._aggre_type))
# GraphSAGE GCN does not require fc_self.
if self._aggre_type == 'gcn':
rst = h_neigh
else:
rst = self.fc_self(h_self) + h_neigh
# bias term
if self.bias is not None:
rst = rst + self.bias
# activation
if self.activation is not None:
rst = self.activation(rst)
# normalization
if self.norm is not None:
rst = self.norm(rst)
return rst코드가 길고 내용이 복잡한것 같다.. 여기서 일단 가장 중요한 부분만 남겨둔 코드를 밑에 작성해 보겠다.( 해당 코드로는 작동 안됩니다. 단순, 개인적으로 중요하다고 판단되는 부분의 코드만 넣어놓겠습니다.)
def forward(self, graph, feat, edge_weight=None):
self._compatibility_check()
with graph.local_scope():
'''
메시지 함수 설정
노드 피쳐중, 이름이 'h'인 피쳐를 복사하여 이름'm'에 저장
'''
msg_fn = fn.copy_src('h', 'm')
h_self = feat_dst
elif self._aggre_type == 'pool':
# feature 'h' 저장
graph.srcdata['h'] = F.relu(self.fc_pool(feat_src))
'''
updata_all(massage 함수, reduce 함수)
updata_all > 연결된 이웃 노드의 feature를 가지고 자신의 feature를 업데이트
'm'이라는 이름의 feature에 max값으로 'neigh'에 저장
따로 그림에서 설명할 예정
'''
graph.update_all(msg_fn, fn.max('m', 'neigh'))
# 추출한 neigh피쳐를 학습가능한 layer을 통과시켜 보다 좋은 feature 생성
h_neigh = self.fc_neigh(graph.dstdata['neigh'])
# GraphSAGE GCN does not require fc_self.
if self._aggre_type == 'gcn':
rst = h_neigh
else:
rst = self.fc_self(h_self) + h_neigh
# bias term
# plus bias
if self.bias is not None:
rst = rst + self.bias
# activation 적용
if self.activation is not None:
rst = self.activation(rst)
# 이웃 노드 feature의 영향을 반영한 결과
return rst딱 이정도의 코드만 봐도 무방하다고 생각한다. 각 코드는 주석처리 한 것을 보길 바란다.
여기서 가장 중요하다고 생각되는 부분은, update_all 함수와 massage 함수를 설정하는 부분이다.
massage 함수(aggregate function)는, 기준 노드와 연결된 다른 노드들의 feature를 어떤 처리 후 모아올 것인지 정의한다.
그 후 reduce 함수를 통해, 어떤 처리(사용자가 원하는 방식)를 하고 받아온 주변 노드 feature를
기준 노드에 반영하기 위해 작업하는 함수가 reduce 함수이다.
이 두 과정을 거쳐 기준 노드를 업데이트 한다.
dgl에서는 update_all(메시지 f , reduce f)를 통해 업데이트를 해준다.
그럼 손으로 한번 풀어보겠다. pool 방식은 아주 간단하기에 할 수 있다.

이처럼 각 노드의 값이 변한 것을 볼 수 있을때, 마지막 파란색으로 표시된 0번째 노드와 3번 노드가 어떻게 해서 저런 값을 가지는지 알아보겠다.

먼저 0노드부터 설명을 해보자면, 전체 그래프에서, 0노드는 시작점이 0노드 / 2노드의 종착점이라는 사실을 알 수 있다.(즉, 방향성이 존재하기 때문에)
0 노드는 0,2노드에만 관계가 있기 때문에, 이 두 노드만 보고 0노드를 업데이트 시킨다.
"pool" 방식의 업데이트는 graph.update_all(msg_fn, fn.max('m', 'neigh')) 해당 코드에서 볼 수 있듯, max값을 가져온다.
즉, 0노드,2노드의 피쳐의 값을 구분하여 가장 높은 값을 새로운 0 노드의 feature로 업데이트 하겠다는 소리다!
바로 위 그림이 그것을 나타냈다. 해당 그림에선 2노드의 값이 모두 다 크기때문에 혼동의 여지가 있으므로 3번 노드에 대해서도 한번 살펴보겠다.

3번 노드는 2,3,5번 노드와 관계가 있다. 즉, 2,3,5번 노드의 피쳐중 가장 큰 값을 가져와 3번 노드의 feature로 업데이트 한다.
위 숫자들을 보면, '열(세로)'기준으로 가장 큰 값을 취해 노드 3의 feature를 업데이트 하였다!
이런 방식으로 node의 피쳐를 업데이트 시켜, 관련이 있는 노드의 정보들을 담을 수 있다.
pool 방식은 정말로 간단하다. 다른 방식의 aggregation도 있으니 한번 코드로 보는걸 추천한다.
+) 추가로, SAGEConv를 여러번 거치게 되면, 직접적인 연관이 없는 노드까지 고려할 수 있는것 같다.
예를 들어,

SAGEConv를 한번 수행하면, 모든 노드는 관계가 있는 노드의 영향을 받아 업데이트 된다.
그렇게 되면, '3번 노드'에 영향을 주는 '2번 노드'는 '1번 노드'의 영향을 받아 업데이트 된다.

그리고, 다시한번 더 SAGEConv를 수행한다고 가정해보면..
'1번 노드'에 영향을 받은 '2번 노드'가 '3번 노드'에 영향을 주기 시작한다.
즉, 1번 노드는 2번 노드를 거쳐 3번 노드에 '간접적으로 영향' 줄 수 있다.
이처럼 여러 layer을 쌓으면 근접한 노드 뿐만 아니라, 멀리 떨어져 있는 노드까지고 고려할 수 있으니 이점 참고하자.
'Deep-learning' 카테고리의 다른 글
| GNN 수학식 뜯어보기 - 2. Graph SAGE (0) | 2022.10.18 |
|---|---|
| GNN 수학식 뜯어보기 - 1. GCN (1) | 2022.10.15 |
| 1. GNN 뜻 (1) | 2022.10.08 |
| 딥러닝 네트워크 종류 (1) | 2022.09.30 |
| 오차 역전파 정리(개인적 생각) (0) | 2022.09.06 |
- Total
- Today
- Yesterday
- python
- 알고리즘
- 오류
- LLM
- GNN
- Tree
- 정리
- 욜로
- 오블완
- c3k2
- 도커
- 파이썬
- yolov11
- 이미지
- YOLO
- GIT
- 초보자
- github
- 티스토리챌린지
- java
- CNN
- 자바
- docker
- 깃
- YOLOv8
- DeepLearning
- 어탠션
- 뜯어보기
- 딥러닝
- V11
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |