
티스토리 뷰
해당 포스팅은 YOLO의 가장 기초가 되는 V1을 정리하고자 합니다.
YOLO의 관심을 가지고 살펴본 분들은 현재 기준 v10까지 나온걸 알고 있을겁니다.
그리고, YOLO가 object detecting, segmentation 등 테스크를 수행 할 수 있다는 것도 알고 있을겁니다.
여기서는 Detecting을 한번 살펴볼까 합니다.
v10까지 나왔지만, v1을 이야기 하는건 YOLO의 기본을 알고 변경되는 사항들을 아는것이 좋다고 생각해서 입니다.
해당 포스팅은 해당 유튜브 영상을 참고하여 작성하였습니다
https://www.youtube.com/watch?v=zgbPj4lSc58&t=765s
YOLO는 실시간으로 사진에서 object(객체)를 인식하여 위치, Class를 분류해주는 모델이다.
기존 RCNN은 사진을 input으로 주면, 위치와 Class를 인식하는 서로다른 모델을 사용하여 2-Stage 모델이라 한다.
이 2-Stage 모델은 정확도는 높을지 모르지만, 속도측면에서 너무 느려 실시간으로 사용하기 어려운 모델이였다.
(RCNN 기준 GPU사용시 5프레임 정도 나온다고 함 )
속도 문제를 해결하기 위해 YOLO는 하나의 모델에서 위치, Class을 동시에 예측하도록 만든 1-Stage 모델이다.
대개 실시간 영상을 탐지해야 한다면 YOLO를 써야한다.
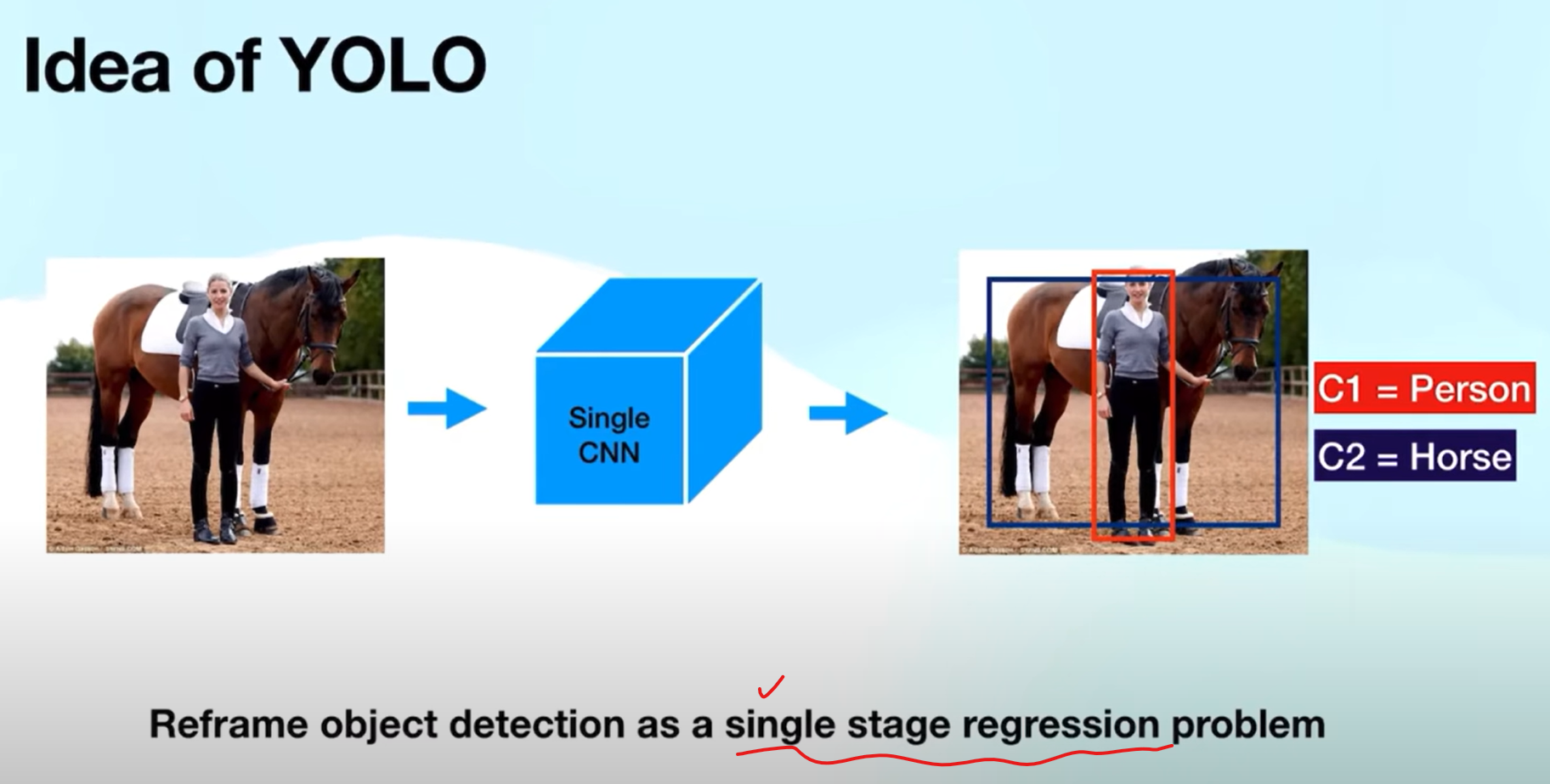
YOLO는 1-Stage regression을 통해 사진안에서의 bbox, class를 예측하는 모델이다.
YOLO의 작동 방식을 한번 살펴보자.

1. 448x448 사이즈로 resize
2. W,H를 측정 사이즈로 나눠 S*S Cell로 구성
3. 각 cell에서 object의 중점인지 아닌지 판단하게 된다.

Bbox 같은 경우, 객체의 중점이 있는 cell의 좌측상단을 기준으로 상대적인 좌표를 표현한다.
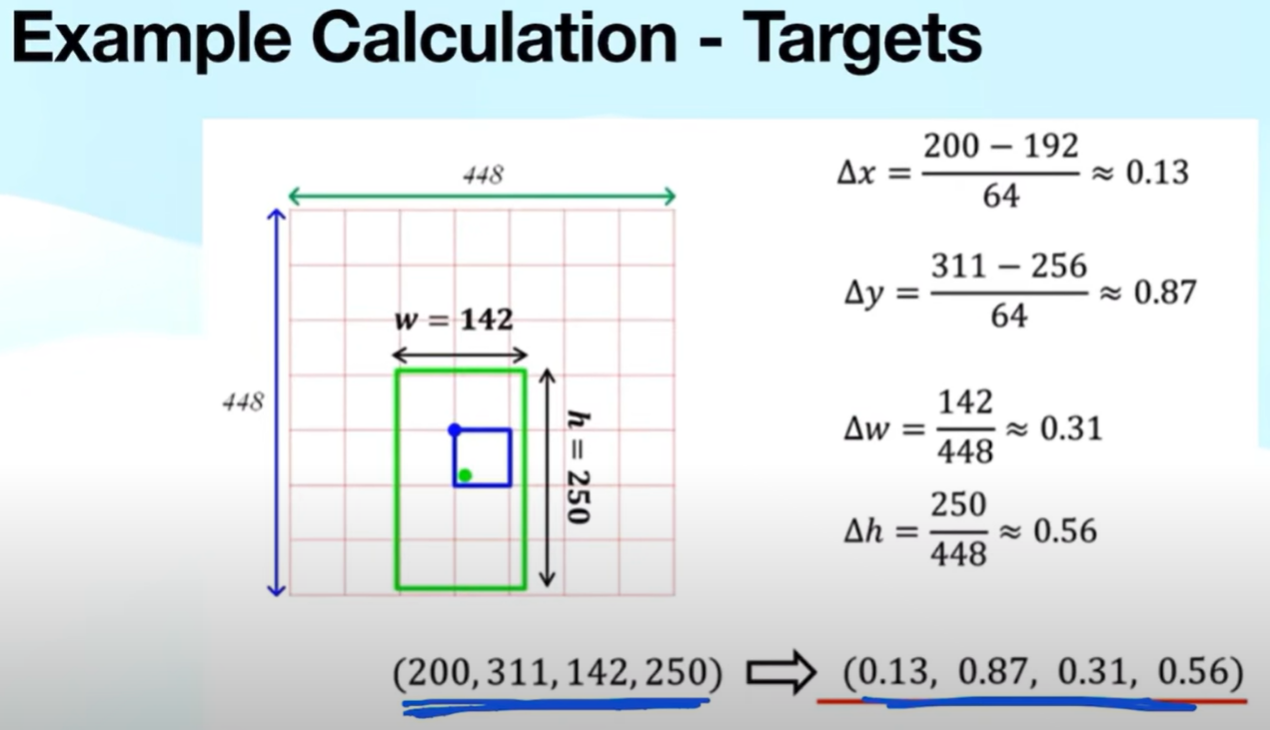
위처럼, 초록색의 점의 좌표를 Bbox로 표현하여 target으로 사용하게 된다. 초록색 점( 객체의 중점 )을 포함하는 cell에서 target을 위와같이 만들게 된다.

그 후 x,y,w,h,c 형태로 값을 생성하게 되는데, 여기서 c는 object score로 해당 셀에 객체가 있을 확률이다.
즉, 중점이 있는 cell에서 c는 1이되고, p1~p20까지 해당되는 부분의 class가 1이 되게 된다.(one hot encoding)
이렇게 regression할 값들의 데이터를 만들게 되는것이다.

YOLO는 1개의 Bbox를 regression하는 것이 아닌, 1개의 Cell당 2개의 Bbox를 예측한다.
즉 위와같이 regression하는 값이 총 30개가 되는것이다.

3차원으로 표현하면 위와같은 그림으로 나타낼 수 있다.
두개의 Bbox를 예측하여 c(object score)가 더 높은 것만 최종적으로 표현하게 된다.

두 Bbox를 예측하고 각각 c를 예측하여 class confidence와 object class를 곱하여 가장 큰 값을 가지는 bbox만을 남기는 후처리를 하게 되는것이다.


모델의 아키텍쳐같은 경우, GoogleNet에서 영감을 받아, Conv layer와 pooling layer을 사용하여 위와같이 7x7x1024 ->flatten -> 1047 -> 7 * 7 *30의 형태로 바꿔준다고 한다. ( 아키텍쳐같은 경우 어려운 개념이 없다 )

학습을 위해 Loss를 정의해야 하는데, 위와같이 정의한다.
1. 각 셀마다 object가 있는지 없는지 GT를 이용해 객체가 있는경우 초록색, 없는경우 빨간색을 통해 Loss를 구한다.
2. object가 있는경우, Bbox의 x,y,w,h의 값 + object score + Class probability 3가지를 고려하여 Loss를 구하며,
object가 없는경우(GT가 없다고 표현하는 경우 ) 는 object Score을 이용하여 Loss를 구하게 된다.

YOLOv1의 가장 큰 문제점은 위와같이 3가지가 존재한다.
1. 최대 49개의 셀만 존재하므로, 각 셀에 Object가 있다면, 맥시멈 49개의 object만 탐지할 수 있다는것.
2. 하나의 cell에 다수의 object의 중점이 몰려있다면, 다수의 object를 탐지못하고, 1개의 오브젝트만 표현 할 수 있다는것
3. 바운딩박스 표현을 상당히 못한다는 것 ( 단순히 중점으로 부터 W/H의 길이만 판단하기 때문... -> anchor Box 개념이 나오게 된 이유 )
간단하게 실시간 탐지 모델 시초가 된 YOLOv1에 대해 정리해 보았다.
v1에서 나타난 단점을 개선하기 위해 어떤 방식으로 개선해 나가는지 살펴보면 더욱 재미있을 것 같다.
'Deep-learning' 카테고리의 다른 글
| YOLOv8 이해하기 (1) - Backbone (0) | 2024.11.07 |
|---|---|
| [Deep Learning] YOLOv2 정리 - Anchor 적용 (0) | 2024.07.15 |
| [Deep learning] pytorch GPU 환경 세팅 (2) | 2023.09.01 |
| [딥러닝] Pooling 정리 (0) | 2023.05.29 |
| [딥러닝] CNN 정리 (0) | 2023.05.29 |
- Total
- Today
- Yesterday
- 파이썬
- 깃
- 욜로
- GIT
- YOLO
- GNN
- 초보자
- yolov11
- c3k2
- CNN
- LLM
- 정리
- 티스토리챌린지
- DeepLearning
- 도커
- 어탠션
- 오블완
- docker
- 이미지
- 알고리즘
- Tree
- 자바
- java
- 뜯어보기
- YOLOv8
- github
- 딥러닝
- python
- 오류
- V11
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |