
티스토리 뷰
1. MaxPool1d
torch.nn.MaxPool1d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
1) kernel_size : 커널 사이즈
2) stride : 커널 이동 정도
3) padding : 좌우 패딩
4) dilation : 커널 거리 정도
5) return_indices : 선택된(maxpooling에 사용한 ) index return 여부
6) ceil_mode : False = 내림을 이용하여 계산 , True = 올림을 이용하여 계산
input_data : (N , C , L) 형태를 띄고있음
N : 갯수 , C : 채널 , L :
2. MaxPool2d
torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
- 1d와 파라미터는 같음
- 차이점 : 가로 , 세로를 탐색하며 진행함
input_data : ( N , C , H , W) or (C, H , W) 형태
3. MaxPool3d
torch.nn.MaxPool3d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
- 파라미터는 동일함
- :
input_data : ( N , C , D , H , W) or ( C , D , H , W)
D : depth임. 간단한 예제로는 '동영상'을 생각하면 됨. 동영상은 다수의 이미지가 연속적으로 실행되는 것임
즉, D는 동영상의 하나하나의 이미지라 생각하면 됨.
4. MAXUNPOOL1D
torch.nn.MaxUnpool1d(kernel_size, stride=None, padding=0)
- 기존 MaxPool과 파라미터 역할을 똑같음.
- 하지만, MaxUnpool1d에 입력된 하이퍼파라미터 기준으로 원래 크기로 복구함
- MaxPool 진행할때 반드시 indices를 받아 maxunpool에 넘겨줘야 함
ex ) (4,)를 maxpool(kernel_size = 2, stride = 1)일 경우 : (3,) 으로 shape이 바뀜
(3,) shape을 MaxUnpool1d(kernel_size = 3, stride= 1)로 할 경우 : (X,) > (3,) Maxpool했다 가정하기 때문에 X는 5가 됨.
(5,)의 형태로 복구함. 단, Maxpool1d의 indice를 반드시 줘야 하므로, 해당 indice에 포함되지 않는 것은 0으로 매칭
pool = nn.MaxPool1d(2, stride=1, return_indices=True) # maxpool인데 return 원소 위치
unpool = nn.MaxUnpool1d(3, stride=1) # unpool
input = torch.randn(2, 4, 4) # N , C , L
print("===== input ======")
print(input)
print("===== output ======")
output, indices = pool(input)
print(output)
print("===== indices ======")
print(indices)
print("===== unpool ======")
print(unpool(output, indices))
'''
===== input ======
tensor([[[-0.3570, 0.4270, -0.2074, -0.4753],
[-1.6985, -0.3672, -1.6550, 0.0117],
[-0.2201, -0.2083, -0.6109, 0.0109],
[ 1.7655, -0.5757, -0.2281, -0.6521]],
[[-1.1077, 0.5474, -1.0665, -1.0088],
[ 0.2854, -0.6010, -0.6670, -1.7012],
[ 0.6512, 1.0288, -0.7627, -1.1278],
[-0.6278, -0.7171, -0.2465, 1.4495]]])
===== output ======
tensor([[[ 0.4270, 0.4270, -0.2074],
[-0.3672, -0.3672, 0.0117],
[-0.2083, -0.2083, 0.0109],
[ 1.7655, -0.2281, -0.2281]],
[[ 0.5474, 0.5474, -1.0088],
[ 0.2854, -0.6010, -0.6670],
[ 1.0288, 1.0288, -0.7627],
[-0.6278, -0.2465, 1.4495]]])
===== indices ======
tensor([[[1, 1, 2],
[1, 1, 3],
[1, 1, 3],
[0, 2, 2]],
[[1, 1, 3],
[0, 1, 2],
[1, 1, 2],
[0, 2, 3]]])
===== unpool ======
tensor([[[ 0.0000, 0.4270, -0.2074, 0.0000, 0.0000],
[ 0.0000, -0.3672, 0.0000, 0.0117, 0.0000],
[ 0.0000, -0.2083, 0.0000, 0.0109, 0.0000],
[ 1.7655, 0.0000, -0.2281, 0.0000, 0.0000]],
[[ 0.0000, 0.5474, 0.0000, -1.0088, 0.0000],
[ 0.2854, -0.6010, -0.6670, 0.0000, 0.0000],
[ 0.0000, 1.0288, -0.7627, 0.0000, 0.0000],
[-0.6278, 0.0000, -0.2465, 1.4495, 0.0000]]])
'''위 처럼 실행 결과 나옴. 즉 MaxUnpool은 MaxPool을 되돌리기 위한 것.
* MaxUnpool2d , MaxUnpool3d도 동일함. ( 파라미터 또한 동일 , shape만 다름 )
5. AVGPOOL1D
torch.nn.AvgPool1d(kernel_size, stride=None, padding=0, ceil_mode=False, count_include_pad=True)
1) count_include_pad : True시 zero-padding을 평균 구하는데 사용함
- MaxPool1d와 파라미터는 동일.
- 하지만 Max값을 취하는 것이 아닌 average 평균을 취함.
- 이해가 안되면 Maxpooling을 다시한번 살펴볼 것
AVGPOOL2D/ 3D
- divisor_override 를 제외한 나머지 파라미터는 1D와 동일
- divisor_override : 평균을 낼때 원소 갯수가아닌 해당 하이퍼파라미터로 나눔
ex) divisor_override = 3
nn.AvgPool2d(kernel_size = 2, stride=1 , divisor_override = 3) 일때
====input====
tensor([[[[ 1.2710, -0.3253, 0.5751, 0.4490],
[ 0.2323, 0.5879, 0.2161, 1.5456],
[ 2.0153, -0.6848, 0.2694, 1.8687],
[-1.0674, 0.5456, -1.6572, -0.1406]]]])
====output====
tensor([[[[ 0.5886, 0.3512, 0.9286],
[ 0.7169, 0.1295, 1.2999],
[ 0.2696, -0.5090, 0.1134]]]])
예를 들어 (1.2710 - 0.3253 + 0.2323 + 0.5879) / 4 가 일반적인 방식
하지만, divisor_override를 지정해 줄 경우 (1.2710 - 0.3253 + 0.2323 + 0.5879) / divisor_override를 수행함.
5. FRACTIONALMAXPOOL2D
torch.nn.FractionalMaxPool2d(kernel_size, output_size=None, output_ratio=None, return_indices=False, _random_samples=None)
- fractionalMaxpool은 특이하게 ouput_size를 원하는대로 맞춰 줄 수 있다. 정수나 비율로 마춰 줄 수 있다.
1) output_size , output_ratio : ouput_size를 지정하여 맞춰줄 수 있다. 단 특이한게... 해당 하이퍼 파라미터를 작성해주면, 알아서 stride를 조정하여 ouput을 뽑아내준다. 단, ouput_size = (1,1)로 할 경우, 좌상단 있는 곳이 아닌.. 우하단에 있는 결과가 나오는 걸로 보아 아무래도 덮어씌우는 것 같다..(잘모르겠음)
2) _random_samples : 모르겠음
- 3D도 2D와 파라미터 동일
6. LPPool1d
torch.nn.LPPool1d(norm_type, kernel_size, stride=None, ceil_mode=False)
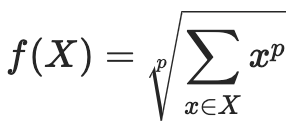
위 수식을 통해 계산하여 pool을 수행하게 된다.
- LPPool은 1d, 2d만 존재한다.
7. ADAPTIVEMAXPOOL1D
torch.nn.AdaptiveMaxPool1d(output_size, return_indices=False)
- 해당 pooling은 output_size를 지정해주어 원하는 형태로 바꿔줄 수 있다.
- kernel_size, stride같은 하이퍼 파라미터가 없다는게 특징임
- 2D / 3D 도 같은 하이퍼 파라미터를 가지고 있음.
8. ADAPTIVEAVGPOOL1D
torch.nn.AdaptiveAvgPool1d(output_size)
- adaptivemaxpool과 동일함.
- reutrn_indices 파라미터가 존재하지 않음 ( 평균을 내는 것이므로 )
- 2D/ 3D도 같은 하이퍼 파라미터를 사용
여기까지 torch docs에 있는 모든 pooling을 살펴보았다.
입맛에 맞게 사용하면 되지만, 사용자가 어떤 차원의 task를 수행하고 있는지 확인 후 사용하면 될 것이다.
'Deep-learning' 카테고리의 다른 글
| [Deep Learning] YOLOv1 정리 - YOLO의 시작 (0) | 2024.07.07 |
|---|---|
| [Deep learning] pytorch GPU 환경 세팅 (2) | 2023.09.01 |
| [딥러닝] CNN 정리 (0) | 2023.05.29 |
| 0. DGL 예제 만들기 프로젝트 (0) | 2022.12.16 |
| 다중공선성을 제거해야할까? (0) | 2022.11.05 |
- Total
- Today
- Yesterday
- 욜로
- 알고리즘
- 이미지
- 오블완
- 티스토리챌린지
- c3k2
- 파이썬
- python
- github
- 딥러닝
- V11
- 도커
- 정리
- YOLO
- 깃
- 어탠션
- Tree
- 자바
- YOLOv8
- CNN
- LLM
- docker
- java
- 초보자
- DeepLearning
- GIT
- 오류
- GNN
- yolov11
- 뜯어보기
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |