
티스토리 뷰
저번엔 티처블 머신을 사용하여 빠르고 간단하며 강력한 모델을 맛봤습니다.
이젠 간단하지만은 않습니다.
하지만 저는 직업도 전문가도 아닌 취미로 하는 것이기에 최대한 간단하게 글을 써보겠습니다.
CNN 예제의 대표주자 MNIST, 검색해보시면 손쉽게 누구나 따라 할 수 있습니다. 한번 해보고 오시면 도움이 되겠죠?

자, 만약 MNIST를 해보셨거나, CNN을 검색해보신 분들은 위와 같은 그림을 한 번쯤을 봤을 겁니다.
이걸 보고 있으면 CNN이 어떤 건지는 대강 알지도 모르지만(난 잘 모르겠음),
정작 우리에게 필요한 건 눈으로 보이는 코드라고 생각합니다.
코드로 바로 넘어가죠.
#코드1
# 모델 구성
new_model = models.Sequential()
# 들어오는 이미지는 100 100 3 / Conv2D(learn total filter, (filter size))
new_model.add(layers.Conv2D(512, (3, 3), activation='relu', input_shape=(100, 100, 3)))
new_model.add(layers.MaxPooling2D((2, 2)))
new_model.add(layers.Conv2D(256, (3, 3), activation='relu'))
new_model.add(layers.MaxPooling2D((2, 2)))
# 데이터 펼치기
new_model.add(layers.Flatten())
new_model.add(layers.Dense(256, activation='relu'))
new_model.add(layers.Dropout(0.5))
new_model.add(layers.Dense(128, activation='relu'))
new_model.add(layers.Dropout(0.5))
new_model.add(layers.Dense(32, activation='relu'))
new_model.add(layers.Dropout(0.5))
new_model.add(layers.Dense(2, activation='softmax'))
new_model.summary()이게 CNN 모델 코드 끝입니다. 위 '그림 1'의 코드는 아니지만, 이러한 식으로 모델을 쌓으면 끝입니다.
모델을 '쌓는다'라는 표현을 했습니다. 말 그대로 '쌓는다'입니다.
최대한 간단히, 이것만 알아도 CNN 모델을 쌓을 수 있을 정도로 설명해보죠.
new_model = models.Sequential() #모델을 정의하겠다 선언model.Sequential은 DIY 모델을 만들기 위해 모델 틀(안에는 아무것도 없는 깡통)을 가져온다고 생각하시면 됩니다.
즉, 모델을 만들기 시작한다는 소리죠.
#512, (3, 3) -> 3x3필터 512개, activation='relu' -> 활성화함수
#input_shape=(100, 100, 3)) -> 2D데이터(여기선 이미지) (가로 세로 RGB)
new_model.add(layers.Conv2D(512, (3, 3), activation='relu', input_shape=(100, 100, 3)))
new_model.add(layers.MaxPooling2D((2, 2)))
여기가 이제 모델을 '쌓는다'라는 곳입니다. 여기서 layers.Conv2D가 이미지의 '특징점'을 추출하기 위한 필터라고 생각하면 됩니다. 그것에 파라미터로 512, (3,3) , activation = 'relu', input_shape=(100,100,3)을 쓰고 있습니다. 하나씩 보죠.
'512, (3,3)'은 3x3 짜리 필터 512개를 생성해 '특징점'을 추출한다는 것이고... 'activation = 'relu''는 활성화 함수를 나타내는데 여러 가지 있습니다. 궁금하시면 찾아보시는 것도 추천드립니다. 'input_shape=(100,100,3)'는 직관적으로 어떤 형태의 2D 데이터가 들어갈 것인가를 설정합니다. (여기선 사전에 100x100 사이즈로 바꾼 사진을 사용했고, 칼라(RGB)이기 때문에 100,100,3)
그다음은 Maxpooling2D입니다. 이건 찾아보세요. 검색하면 gif로 훨씬 더 쉽게 이해할 수 있습니다.
new_model.add(layers.Flatten()) # 2차원 1차원으로 펼침
new_model.add(layers.Dense(256, activation='relu')) # 생각하는 공간
new_model.add(layers.Dropout(0.5))
new_model.add(layers.Dense(128, activation='relu'))
new_model.add(layers.Dropout(0.5))
new_model.add(layers.Dense(32, activation='relu'))
new_model.add(layers.Dropout(0.5))
new_model.add(layers.Dense(2, activation='softmax'))
new_model.summary()Flatten()은 평탄화(?)라고 생각하시면 됩니다. 위에서 우리는 사진 (가로 x 세로) '2차원' 데이터를 입력해 '2차원' '특징점'들을 찾아낸 겁니다. 이 '2차원'을 연산하기 쉽게 '1차원'으로 바꿔준다고 생각하세요.(다차원일수록 연산이 빡세잖아요)
그렇게 2차원을 1차원으로 펼치고 이 펼친 데이터를 256개의 노드에게 '모두' 보냅니다. 여기서 '노드'란 판단 내리는 '사람'이라고 생각합시다. 즉 우리는 256명의 사람을 생성해 256명에 '모두' 같은 데이터('사건'이라고 생각)을 보내주었습니다.
여기서 '모두'라는 표현을 사용한 이유가 있습니다. 사람들도 1개의 사건을 개개인마다 다르게 생각하기 때문에 256명의 사람에게 각 사건을 보냈다고 생각하면, 256개의 생각이 나오겠죠? 이렇게 각각의 생각을 들어보기 위해 '모두'에게 '사건'을 보내보는 거죠. 그렇게 256개의 생각을 다시 128명의 사람에게 보내면 256명의 생각을 128명의 사람들이 각각 어떠한지 생각/판단합니다. 이런 과정을 반복하여 32명의 생각을 결국 2명의 사람이 어떠한지 판단합니다.
여기선 결국 아이유냐? 수지냐?를 판단하게 되는 거죠.
어렵죠? 그냥 이렇게 사용한다만 알고 합시다. 우린 취미니까요.
마지막으로 Dropout은... 과적합(overfitting)을 막기 위한 방법으로 256명 사람 중 128(Dropout(0.5) = 50%의 미) 명의 사람의 생각만 들어서 한쪽으로 편향된 생각이 덜 나오도록 한다고 보시면 됩니다. 그냥 과적합 막을라고 하는 거예요.
이러한 과정을 거치면 나만의 DIY CNN 모델을 형성했습니다. 위 코드 1보다 Conv2D, Dense 사이즈를 크게 해주면 더욱 넓은 생각을 할 수 있겠고, 층을 여러 개 쌓으면 깊게 생각할 수 있겠죠? (물론 컴퓨터 성능이 좋다면)
자, 이렇게 만든 모델은 티처블머신과 얼마나 다른지 한번 봅시다.

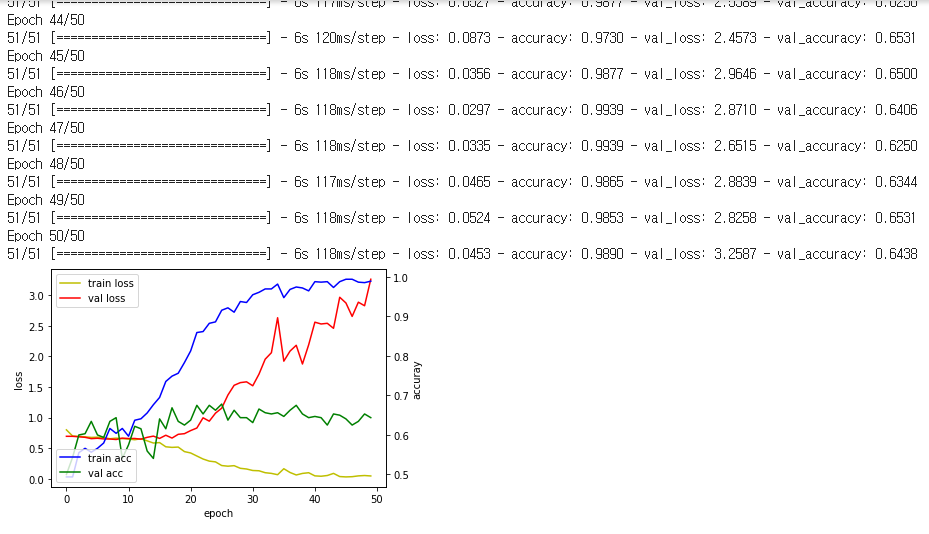
왼쪽은 티처블 머신 / 오른쪽은 DIY CNN 모델입니다. (훈련에 사용한 데이터 셋은 둘 다 동일함)
처참하죠? 정확도도 64% 정도 나오네요. (티처블 머신은 79%) 패배했습니다. 당연히 구글이 함께한 모델과 비교할 수 없죠. 물론 잘 학습된 모델이라고 말할 순 없습니다.(둘 다) 이유는 loss도 봐야 하기 때문에... 이건 나중에 언급하도록 하겠습니다.
이렇게 DIY CNN 모델을 만들어 보았습니다. '층'도 여러 개 쌓아보시고 '노드'도 여러 개 만들어보고 '학습률'도 바꿔보시고 등등... 여러 시행착오를 통해서 여러분들이 원하는 결괏값을 얻을 수 있도록 CNN 모델을 만들어 보는 것을 추천해드립니다. 그럼.. 다음에는 이 처참한 정확도를 개선해봅시다.
'Deep-learning' 카테고리의 다른 글
| [Deep-learning] 5. 흙수저의 마지막 희망 Google Colab. (0) | 2020.08.15 |
|---|---|
| [Deep-learning] 4. VGG16과 Fine tuning의 결합 (0) | 2020.08.13 |
| [Deep-learning] 3. 흙수저의 이미지 분류를 위한 도구 VGG16 (Transfer learning - 전이학습) (1) | 2020.08.12 |
| [Deep-learning] 1. 빠르게, 간단하게, 강력하게 CNN 맛보기 (0) | 2020.08.11 |
| [Deep-learning] 0. 딥러닝으로 무엇을 할까? (0) | 2020.08.11 |
- Total
- Today
- Yesterday
- CNN
- 파이썬
- 깃
- 오류
- 오블완
- GNN
- github
- yolov11
- DeepLearning
- 도커
- YOLO
- Tree
- LLM
- YOLOv8
- 욜로
- 티스토리챌린지
- 자바
- 정리
- 딥러닝
- c3k2
- 초보자
- docker
- 알고리즘
- 이미지
- 어탠션
- V11
- 뜯어보기
- java
- python
- GIT
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |