
티스토리 뷰
안녕하신가.
저번에 VGG16을 이용하여 Transfer-learning 전이 학습을 대~~충 봤다. 그 결과 70~85%가 나오는 기염을 토했다.(학습이 잘 된 모델이라곤 안 했다.) 하지만, 딥러닝에선 정확도 뿐만 아니라 그래프의 모양, loss 또한 살펴볼 필요가 있다.
이 그림을 보자.

이 그림은 learning rate에 따른 loss를 말한다. 즉, 여기서 빨간색의 그림과 유사하게 돼야 어느 정도 잘 학습된 모델이라고 볼 수 있고, 여기서 정확도도 따져 과대적 합(overfitting)인지 과소 적합(underfitting)인지 따져야 하지만... 넘어가자. 복잡하다. 여기선 그냥 loss가 빨간색 선처럼 줄어야 좋다고만 알고 있자.
여기서 저번 VGG16으로만 학습한 그래프를 보면
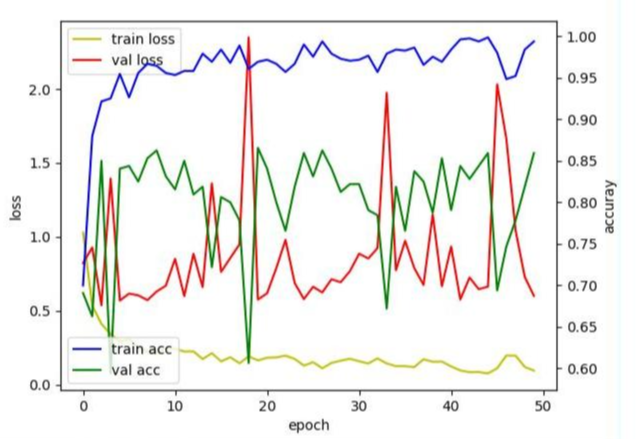
노란색 선이 train loss , 빨간색 선이 val loss .... 딱 봐도 노란색 선(train)은 어느 정도 [그림 1.]에서의 빨간색 선과 유사(?) 하다고 볼 수 있지만, 빨간색 선(validation)은 정말 이상적이지 않다. 필자는 epoch이 적어서 그런 줄 알고 500번으로 늘려봤다.
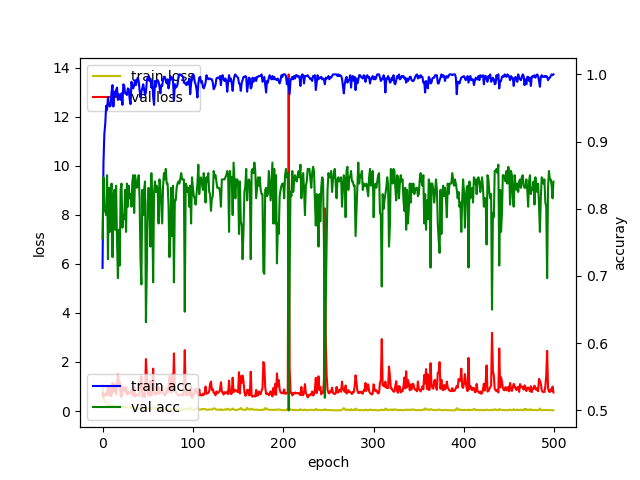
응~ 똑같아~ 개판이다. 이것이 VGG16 transfer-learning의 한계라고 개인적으론 생각한다. 물론 개인적인 생각이다. 오해하지 말자.
그럼 이 문제를 어떻게 해결할까? 이 문제를 해결하기 위해서 fine-tuning을 한다고 한다.
Fine-tuning... 적합하게 튜닝하기(?) 정도 될까? 어느 정도 의미는 맞을 것이다.
맞다. 튜닝을 하는 것이다. 어떤 것을? VGG16 모델의 CNN을!
VGG16은 이미 훌륭하게 특징점을 추출할 수 있다고 저번 시간에 말했다. Fine-tuning은 VGG16의 훌륭한 특징점 추출 성능을 우리가 직면한 문제에 더욱 적합하게 튜닝하는 것이다.
그러면 우리가 해결하고자 하는 문제점에 더욱 알맞게 VGG16을 맞출 수 있는 것이다. 그럼 당연히 성능도 UP/ 좋은 모델을 만들 수 있을 것이다.
그럼 어떻게 VGG16을 튜닝하도록 접근할 수 있을까? 코드로 보자.
from keras import applications
model = applications.VGG16(weights='imagenet', include_top=False, input_shape=(image_size, image_size, 3))
for layer in model.layers[:-10]:
layer.trainable = False
for layer in model.layers:
print(layer, layer.trainable)
#이런식으로 VGG16 구성을 볼 수 있다 여기서 false -> 훈련 X / true -> 훈련 o
#<tensorflow.python.keras.engine.input_layer.InputLayer object at 0x7fd0c015d208> False
#<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fcfb24f9ef0> False
#<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fd0c015df60> False
#<tensorflow.python.keras.layers.pooling.MaxPooling2D object at 0x7fcfb244bda0> False
#<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fd0c01aa2e8> False
#<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fd0c015d048> False
#<tensorflow.python.keras.layers.pooling.MaxPooling2D object at 0x7fcfb24ac5c0> False
#<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fcfb24b4588> False
#<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fd0d8152518> False
#<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fcfb241c240> True
#<tensorflow.python.keras.layers.pooling.MaxPooling2D object at 0x7fcfb2425550> True
#<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fcfb241c908> True
#<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fcfb241c550> True
#<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fcfb242c7b8> True
#<tensorflow.python.keras.layers.pooling.MaxPooling2D object at 0x7fcfb2434ac8> True
#<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fcfb242ce80> True
#<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fcfb242cac8> True
#<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fcfb243cd30> True
#<tensorflow.python.keras.layers.pooling.MaxPooling2D object at 0x7fcfb23c6f98> True이게 끝이다. 'include_top=False'를 하면 Flatten() 하는 곳을 포함하지 않는다는 뜻이다.(저번에 설명했나?)
그 후 model.layers를 통해 VGG16의 특정 CNN(layer)에 접근하여 나의 문제에 맞도록 훈련할지 안 할지 설정해 주면
fine-tuning은 끝... 간단하다. 주의할 점이 하나 있는데, fine-tuning을 하고 Flatten()에는 이미 훈련된 모델을 얹어야 한다. 무슨 말인고 하면.. 코드로 봐보자.
top_model = Sequential()
top_model.add(Flatten(input_shape=model.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dense(2, activation='softmax'))
top_model.load_weights(top_model_weights_path) #이미 학습된 Flatten()을 불러와야함! 반드시
new_model = Sequential() # VGG16(fine-tuning) + Faltten 모델(이미 학습됨)을 합쳐서 모델생성
for l in model.layers:
new_model.add(l)
for l in top_model.layers:
new_model.add(l)이런 식으로 해줘야 한다는 소리다. 즉 VGG16 + Flatten 모델은 같다. 하지만 VGG16은 fine-tuning 설정을 해줬고, Flatten() 모델은 저번 시간에 학습된 모델을 그대로 사용해야 한다. 반드시! 안 그러면... 효과가 없당....
이렇게 설정을 해놓고 100epoch만 돌려보자.... 말이 100epoch 이지... 1epoch에 90~100초 정도 걸린다.. 즉 2시간은 돌려야 한다는 소리다... 성능이 안 좋은 컴퓨터는 이렇게 고생을 한다....
Fine-tuning한 모델을 돌려보면 이렇게 나온다!
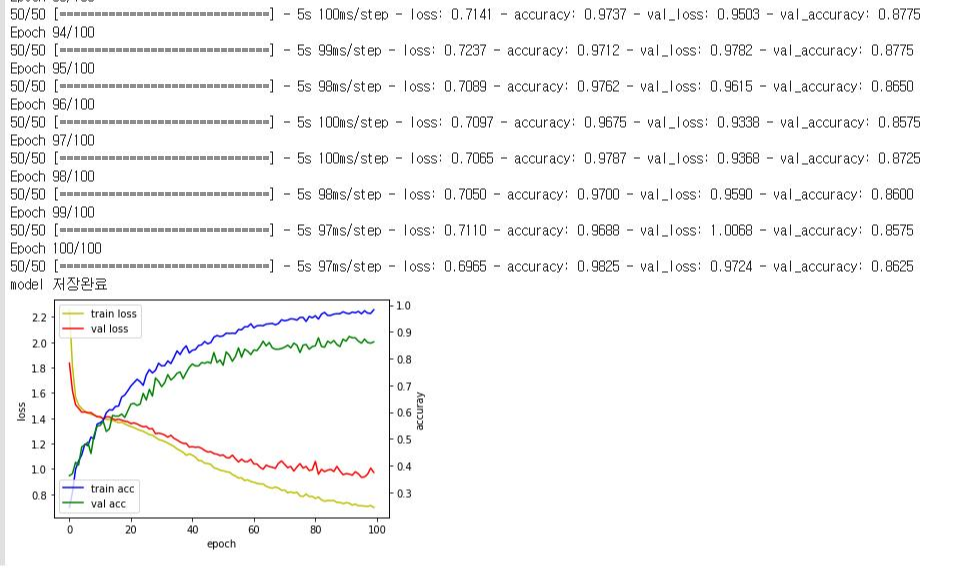
[그림 4]의 노란색, 빨간색 선을 보아라 위에서 난장판이던 그래프와는 너무나도 다르다! 안정적이며 정확도 또한 70~85%가 아닌 80% 이상을 꾸준히 유지하고 있다. 마지막은 86%! 이것이 fine-tuning의 힘이다. (물론 여기엔 +a 가 더 들어가긴 했다. 이 내용은 다음에 다룬다!)
이것저것 여러 개의 fine-tuning 한 모델을 만들어 최상의 성능의 내는 모델을 찾아내는 것도 일이다. 왜냐면 컴퓨터가 안 좋으면 아까 말했 듯 90~100초(1에폭 당) 걸린다. 만약 이걸 100번 한다면.... 적어도 9000초... 150분... 2시간 30분.... 절망이다. 하지만 [그림 4.]에선 5초? 정도밖에 안 걸렸다. ?오잉????? 분명 필자는 컴퓨터가 안 좋다고 했는데????라고 생각할 것이다. 비밀은 바로 'Colab'! 이건 바로 다음 글에 올리도록 하겠다.
자 오늘은 Fine-tuning에 대해 설명(?)하고 그래프까지 보았다. 이걸 잘 이용하면 보다 훌륭한 모델까지 만들 수 있을 것이다. 다음에 보자!
'Deep-learning' 카테고리의 다른 글
| [Deep-learning] 6. 오버 피팅(Overfitting)을 막기 위한 발악 (0) | 2020.08.15 |
|---|---|
| [Deep-learning] 5. 흙수저의 마지막 희망 Google Colab. (0) | 2020.08.15 |
| [Deep-learning] 3. 흙수저의 이미지 분류를 위한 도구 VGG16 (Transfer learning - 전이학습) (1) | 2020.08.12 |
| [Deep-learning] 2. DIY CNN모델 쌓기 (0) | 2020.08.11 |
| [Deep-learning] 1. 빠르게, 간단하게, 강력하게 CNN 맛보기 (0) | 2020.08.11 |
- Total
- Today
- Yesterday
- 오류
- CNN
- 뜯어보기
- 도커
- 오블완
- 초보자
- yolov11
- LLM
- YOLO
- java
- GNN
- docker
- V11
- c3k2
- 티스토리챌린지
- 이미지
- 딥러닝
- 자바
- Tree
- 어탠션
- DeepLearning
- YOLOv8
- GIT
- 깃
- 욜로
- 알고리즘
- python
- 파이썬
- github
- 정리
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |