
티스토리 뷰
https://sims-solve.tistory.com/131
YOLOv11 이해하기 (2) - Neck
https://sims-solve.tistory.com/130 YOLOv11 이해하기 (1) - Backboneyolov11은 Backbone + neck + head 총 3가지로 나눠져 있다고 한다. ( backbone + head 로만 나누기도 한다.)이중, 이번에는 Backbone을 살펴보고자 한다.yolov1
sims-solve.tistory.com
지금까지 backbone, neck 부분을 살펴봤고, 이번에는 마지막으로 Head 부분을 살펴보고자 한다.
yolo의 가장 큰 특징은 3개의 서로다른 size의 shape을 가지는 detection을 이용하여, big , middle, small object의 탐지 성능을 높이려는 시도가 있었다는 점이다.
즉, 3개의 Detection에서는 탐지하고자 하는 object의 크기가 서로 다르다고 생각하면 된다.
yolov8에서는 80* 80 / 40 *40 / 20*20 크기를 가지고 진행을 했으며, yolov11에서도 크게 다르지 않다.
Head 부분을 코드를 따라가면서 shape의 형태를 살펴보고, 내부적으로 변경된것이 있는지 살펴보고자 한다.
Yolov8과 크게 다르지 않으므로 천천히 순서대로 진행하면 큰 문제는 없을 것이다.
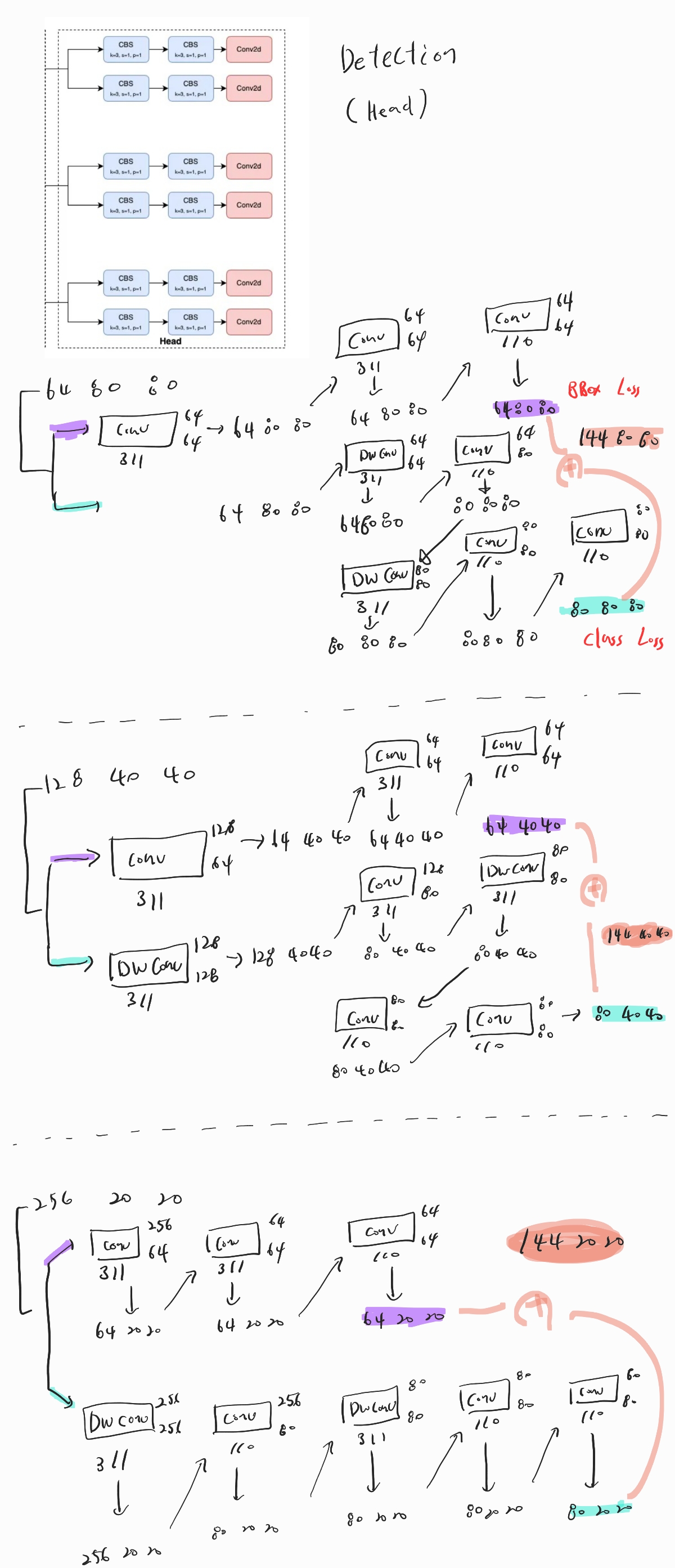
위에서 말했듯 3개의 서로다른 Detector를 진행하게 되며, 이때 output shape은 위와 각각 같다.
Detector는 Box, Class Loss를 위해 나눠서 진행하지만, 결국 concat 하여 (144 , x , x ) 형태로 나오게 된다.
(만약, 분류하고자 하는 Class number 수가 다르면 144가 아니다 )
여기까지 완전히 yolov8과 동일한 모습을 볼 수 있다.
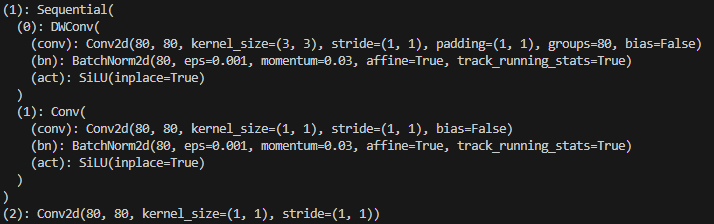
하지만 내부적으로 한가지 변화한 사실을 볼 수 있다.
일반적으로 Conv Block을 사용하지만, yolov11에서는 DWconv라는 것을 사용하는 것을 볼 수 있다.
가장 큰 차이점은 Conv2D의 group 파라미터가 사용됐다는 점이다.
group을 지정하면, 지정한 수 만큼 split을 한다고 생각하면 쉽다.
즉, 일반적인 상황에선 (80,3,3)의 커널을 80개 만들어 진행을 한다. 즉 3*3*80*80의 파라미터가 든다.
하지만 group = 80이라 지정해놓으면, ( 1,3,3)의 커널을 80개 만들어 각각 나뉘서 진행하기 때문에 3*3*1*80의 파라미터가 든다. 결국 경량화의 목적도 있는것으로 보인다.
추가적으로 시각적으로 살펴보고자 한다면 아래의 글을 추천한다.
[액션파워 LAB] pytorch Conv2d parameter 파헤치기
AI 분야에서 가장 대표적인 신경망인 2차원 합성곱 층(2D convolutional layer)의 구현체 pytorch 라이브러리의 torch.nn.Conv2d 클래스를 아주 자세하게 파헤쳐 보겠습니다.
actionpower.medium.com
이렇게 Yolov11의 Detector 부분도 살펴봤다. Yolov8의 디텍션 부분과 98% 동일하여 둘 중 하나만 명확히 알아도 최신 YOLO의 아키텍쳐는 모두 안다고 볼 수 있겠다.
이제 남은건 Loss를 구하는 방법이 남았다. 다음에는 Loss를 구하는 방식에 대해서 살펴보도록 하겠다.
'Deep-learning' 카테고리의 다른 글
| [LLM] huggingface LLM 기본 내용 ( 양자화 ) (0) | 2025.01.30 |
|---|---|
| YOLOv11 이해하기 (4) - Loss (0) | 2024.11.19 |
| What is Attention?(어텐션 이란?) (0) | 2024.11.17 |
| YOLOv11 이해하기 (2) - Neck (0) | 2024.11.16 |
| YOLOv11 이해하기 (1) - Backbone (2) | 2024.11.15 |
- Total
- Today
- Yesterday
- c3k2
- 정리
- 알고리즘
- DeepLearning
- 도커
- 파이썬
- docker
- 어탠션
- LLM
- 이미지
- CNN
- 오블완
- 자바
- YOLOv8
- 티스토리챌린지
- 뜯어보기
- 오류
- Tree
- V11
- GNN
- java
- GIT
- 초보자
- 딥러닝
- github
- yolov11
- python
- 욜로
- YOLO
- 깃
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |