
티스토리 뷰
https://huggingface.co/docs/transformers/ko/llm_tutorial
대규모 언어 모델로 생성하기
LLM 또는 대규모 언어 모델은 텍스트 생성의 핵심 구성 요소입니다. 간단히 말하면, 주어진 입력 텍스트에 대한 다음 단어(정확하게는 토큰)를 예측하기 위해 훈련된 대규모 사전 훈련 변환기 모
huggingface.co
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"mistralai/Mistral-7B-v0.1", device_map="auto", load_in_4bit=True)
pretrained_model_name_or_path : huggingface에 등록된 모델 명 or 다운로드 한 모델 위치
device_map : CPU/GPU select
load_in_4bit : 4bit Quantization( 양자화 ) -> 모델 용량 Down / 추론속도 UP/ 정확도 Down ( 단, 미래는 없어질 파라미터 이므로, 'BitsAndBytesConfig'를 통해 진행하면 좋다.)
** load_in_4bit = True를 했을때 정말 4bit으로 변경될까??
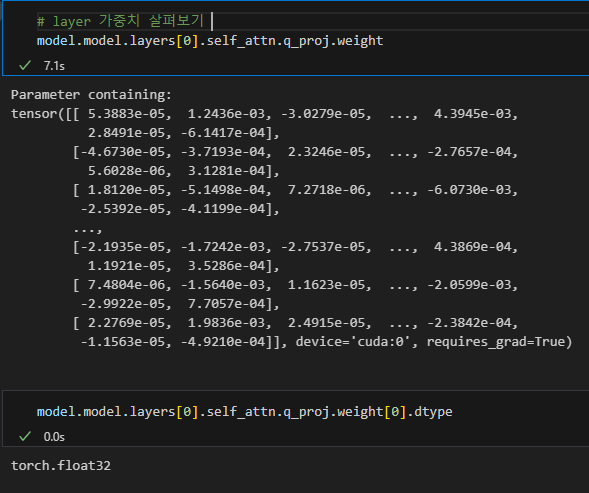
load_in_4bit없이 모델을 불러오면, 위와같이 float32로 dtype이 정해지는 것을 볼 수 있음.
load_in_4bit을 한 후 모델을 불러왔을때 아래와 같음. 특이한건, dtype이 torch.uint8로 저장되며, 값도 Params4bit이라는 것에 들어가게 됨.

여기서 알 수 있는건
1. 4bit 양자화를 하더라도 저장되는 dtype은 8bit으로 저장하는 것을 알 수 있음.
2. Params4bit이라는 Class를 통해 값이 저장되는 것을 볼 수 있음
그럼, load_in_8bit이라면 어떻게 될까?

이때는 int8로 예상 가능한 type이 나온다. 또, Int8Params라는 걸 이용해 값을 저장한다.
** 결론
즉, 4bit, 8bit은 어떠한(?) 방법을 통해 'int'형으로 바꾸는 것을 볼 수 있었다.
( 어떻게 변경하는지는 추후에 알아봐야 함)
torch_dtype
그럼, 모델을 정의할때 torch_dtype이란게 있는데 이건 뭘까?
기본적으로 torch.nn.LayerNorm과 같은 다른 모듈은 torch.float16으로 변환됩니다. 원한다면 torch_dtype 매개변수로 이들 모듈의 데이터 유형을 변경할 수 있습니다
위와같은 내용이 있는 허깅페이스에서 볼 수 있다. 한마디로, 양자화를 하지 않는 부분의 layer의 type을 setting 한다는 의미다.



torch_dtype를 float32로 설정하여 진행하면, 양자화 되지 않는 layer들은 torch.float32로 설정되는 모습을 볼 수 있다.
그럼, default( torch.float16)으로 진행하면 어떻게 될까?
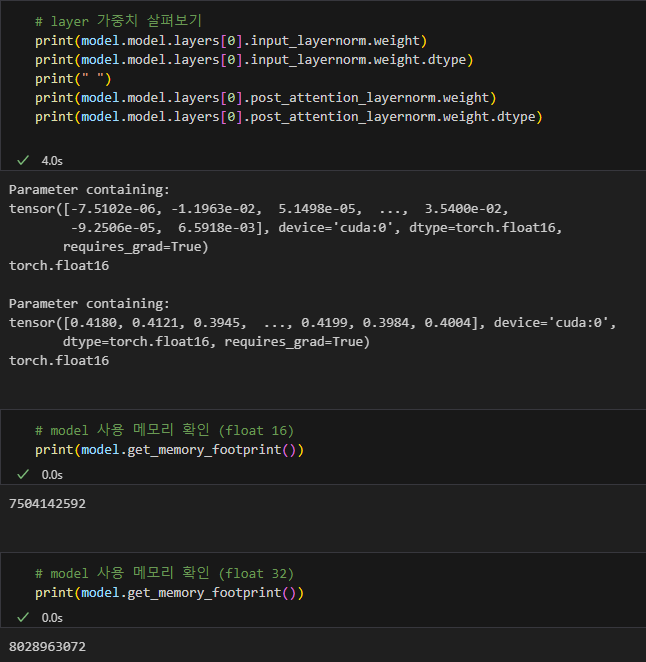
양자화가 적용되지 않는 layer들은 float16으로 되는 것을 알 수 있다.
float32와 float16의 모델 크기도 살펴보니, 당연히 float16의 모델 크기가 작은것을 볼 수 있었다.
BitsAndBytesConfig 파라미터 ( 4bit )
bnb_4bit_compute_dtype : input type의 형태가 다를시, 계산 타입을 변경하여 진행 ( 속도의 장점을 얻을 수 있음 )
FP32 -> fp16 , bf16 형태로 계산 진행 ( 기본은 float32)
--> 추가 설명
양자화에서 forward, backward 는 4 bit 에서 일어나지만, gradient computation 과정에서는 float16, bfloat16, float32 등의 자료형으로 변환하여 진행해야 한다. 그러므로, 이에 맞는 자료형을 골라서 넣어주면 된다.
bnb_4bit_quant_type : bnb.nn.Linear4Bit 레이어 안에서 사용할 양자화 타입을 선택하는 것 ( fp4, nf4로 할 수 있음 )
+bnb_4bit_quant_type 은 bnb.nn.Linear4bit layer의 quant_type을 설정해주는 것
**FP4, NF4란?
FP ( Floating Point ) -> 부동소수점으로 표현, 상대적으로 높은 정밀도 / 상대적으로 낮은 연산 속도
NF ( Non- Floating Point ) -> 정수로 표현 , 상대적으로 낮은 정밀도 / 상대적으로 높은 연산 속도
bnb_4bit_use_double_quant : 양자화 이후 한번 더 양자화 진행여부
https://huggingface.co/docs/transformers/ko/quantization/bitsandbytes
bitsandbytes
bitsandbytes는 모델을 8비트 및 4비트로 양자화하는 가장 쉬운 방법입니다. 8비트 양자화는 fp16의 이상치와 int8의 비이상치를 곱한 후, 비이상치 값을 fp16으로 다시 변환하고, 이들을 합산하여 fp16으
huggingface.co
'Deep-learning' 카테고리의 다른 글
| [LLM] Fine-Tuning (0) | 2025.02.06 |
|---|---|
| [LLM] Tokenizer 기본 (0) | 2025.02.01 |
| YOLOv11 이해하기 (4) - Loss (0) | 2024.11.19 |
| YOLOv11 이해하기 (3) - Head (0) | 2024.11.18 |
| What is Attention?(어텐션 이란?) (0) | 2024.11.17 |
- Total
- Today
- Yesterday
- 알고리즘
- LLM
- GNN
- 욜로
- 이미지
- YOLO
- 자바
- 뜯어보기
- V11
- yolov11
- 깃
- 오블완
- 오류
- YOLOv8
- 도커
- 티스토리챌린지
- c3k2
- DeepLearning
- Tree
- 초보자
- GIT
- github
- 딥러닝
- 파이썬
- 어탠션
- CNN
- 정리
- java
- docker
- python
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |