
티스토리 뷰
Tokenizer 기본 선언 방식
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(CFG["model"])기존 본인이 사용하고자 하는 모델명, Tokenizer 위치를 파라미터에 넣어 불러오면 끝.
하지만, 위 방식으로 진행하면, 모델따로 토크나이저 따로 불러와 사용해야함.
이걸 한번에 할 수 있는게 바로 pipeline 함수.
# pipline을 이용하여 추론
import transformers
from transformers import AutoModelForCausalLM ,BitsAndBytesConfig
# 4bit quantization
quantization_config = BitsAndBytesConfig(load_in_4bit=True,
bnb_4bit_quant_type = "nf4")
# pipeline으로 진행하면, 자동으로 tokenizer도 불러옴
pipline = transformers.pipeline(
"text-generation",
model = CFG["model"],
model_kwargs = {'quantization_config' : quantization_config},
device_map="auto"
)위처럼 transformers.pipeline을 사용시 모델과 해당 모델에 사용되는 토크나이저를 한번에 받을 수 있음.
pipline.tokenizer
pipline.model로 기존처럼 모델과 토크나이저에 접근이 가능하며 사용할 수 있음.
Chat 형식
https://huggingface.co/docs/transformers/main/ko/chat_templating
채팅 모델을 위한 템플릿
(번역중) 효율적인 학습 기술들
huggingface.co
LLM 하면서 가장 많이 활용하는 것이 chat모델일 것임.
모델명-chat / 모델명-it 과 같이 허깅페이스에 저장된 모델들이 있는데, 이것들이 바로 채팅을 위해 finetuning된 모델임.
기존 대기업에서 모델을 개발하여 배포하는 것 ( ex. google/gemma-7b )은 next token generation으로 pretrain한 모델이다.
이러한 모델을 base로 사용자들은 번역, 요약과 같은 여러가지 DownStreamTask로 FineTuning을 진행한다.
chat 형식으로 답변을 출력할 수 있도록 DownStreamTask를 진행한다고 생각하면 된다.
그럼 여기서 가장 헷갈렸던 부분이 있다. "어떤 형식으로 chat Template를 구성해야 하는가? "
여러가지 모델이 있고, 각 모델별 스페셜 토큰도 다른데 구성을 어떻게 해야할까...
결론
1. Pretrain 된 모델을 이용할 경우에는 자유롭게 만들어 주면 됨 ( 상대적으로 자유로움 )
2. 이미 chat/it 형식으로 finetuning된 모델을 이용할 경우, 기존 학습에 사용한 template를 사용하면 됨
그럼, 1번의 경우는 큰 문제가 없지만, 2번의 경우는 어떤 형식인지 알아보기 위한 방법은 아래와 같음.
# pipline을 이용하여 추론
import transformers
from transformers import AutoModelForCausalLM ,BitsAndBytesConfig
import torch
import json
import huggingface_hub
with open('./settings/config.json') as f:
CFG = json.load(f)
# Private Token value input & login
huggingface_hub.login(token = CFG["TOKEN"])
CFG["model"] = "rtzr/ko-gemma-2-9b-it"
# 4bit quantization
quantization_config = BitsAndBytesConfig(load_in_4bit=True,
bnb_4bit_quant_type = "nf4")
# pipeline으로 진행하면, 자동으로 tokenizer도 불러옴
pipline = transformers.pipeline(
"text-generation",
model = CFG["model"],
model_kwargs = {'quantization_config' : quantization_config},
device_map="auto"
)위처럼 gemma를 it형식으로 학습시켜 놓은 모델을 pipeline을 이용하여 모델과 토크나이저를 불러왔다.

그 후, messages를 위 형태처럼 만들어주고, apply_chat_template를 이용하여 넣어주면 해당 모델에서 사용한 채팅형식에 맞춰서 프롬프트를 생성할 수 있다.
prompt의 출력물을 보면, <bos> <start_of_turn> <end_of_turn> 형식으로 작성되는 것을 볼 수 있는데,
학습시킬때 위와같은 형식을 바탕으로 학습을 진행하여 해당 it 모델의 chat template은 위와같다.
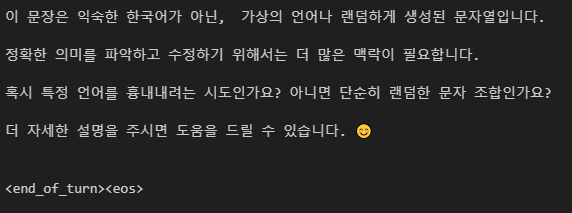
생성을 진행해보면 아래와 같은 결과물을 얻을 수 있다.(pipeline으로 추론을 진행하면, 끝나는 지점의 스페셜토큰을 볼 수 없기에 기존 generate 함수를 이용하여 진행하였다.)
여기서 마지막 스페셜 토큰으로 <end_of_turn> <eos> 가 생성되어 더이상 생성을 멈춘 것도 볼 수 있다.
'Deep-learning' 카테고리의 다른 글
| KL Divergence 정리 (0) | 2025.10.19 |
|---|---|
| [LLM] Fine-Tuning (0) | 2025.02.06 |
| [LLM] huggingface LLM 기본 내용 ( 양자화 ) (0) | 2025.01.30 |
| YOLOv11 이해하기 (4) - Loss (0) | 2024.11.19 |
| YOLOv11 이해하기 (3) - Head (0) | 2024.11.18 |
- Total
- Today
- Yesterday
- 자바
- 도커
- V11
- 파이썬
- CNN
- github
- 어탠션
- YOLO
- 오블완
- 정리
- 초보자
- docker
- Tree
- 알고리즘
- LLM
- 깃
- yolov11
- GNN
- YOLOv8
- 딥러닝
- 오류
- GIT
- 이미지
- DeepLearning
- 티스토리챌린지
- 욜로
- 뜯어보기
- java
- python
- c3k2
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |