
티스토리 뷰
의사결정트리는 Forest 계열에 가장 base로 사용되는 모델이다.
RandomForest , Extra Tree, 일부 Boosting계열 모델에서 n개의 decision tree가 사용되므로
의사결정 트리를 상세하고 정확하게 공부하고 넘어가고자 글을 작성한다.
이름에서도 알 수 있듯 tree모양을 띄는 알고리즘이다. 자료구조에서 Tree구조를 안다면 보다 도움이 될것이다.

이러한 구조를 Tree구조라고 한다. 하나의 root node로부터 자식노드로 점점 깊이 뻗어나가는 모습을 볼 수 있다.
Tree 구조의 자식node로 분기를 하여 탐색에 용이하도록 해주는 장점이 있다.
왜 트리인고 하니..


그래프를 뒤집어보면 위로 뻗어있는 나무와 비슷하다. 뿌리로부터 가지가 뻗어나가는 모습...
DecisionTree도 root 노드부터 분기를 통해 분류/회귀의 값을 판단할 수 있는 leaf node까지 생성하여 예측값을 뽑아내게 된다.
그럼 이제 자세히 한번 살펴보자.
DecisionTree는 위에 말했듯, 분류(Classification) 과 회귀(Regression) 두 task에 사용할 수 있다. 일단, 분류먼저 살펴보기로 하자.
1. Tree를 어떻게 구성할까?
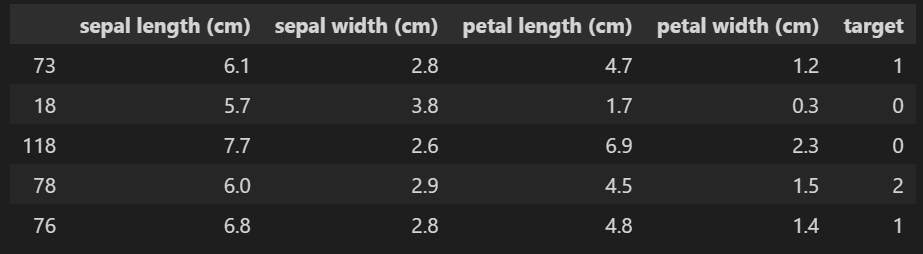
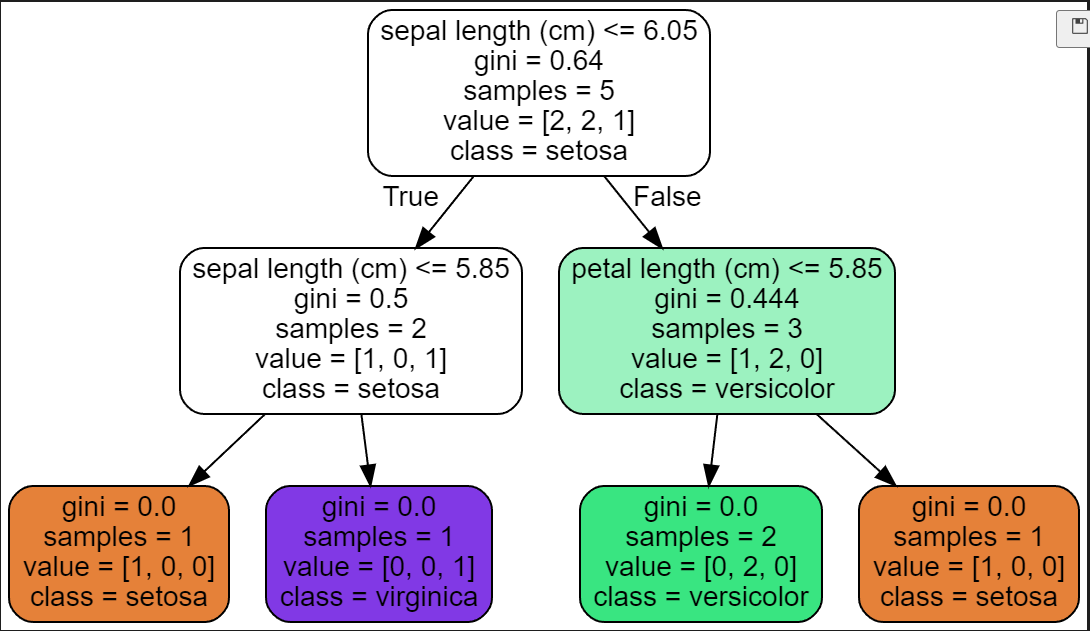
[사진1]과 같이 데이터가 있으면 Decision Tree는 [사진2]와같이 Tree를 구성하는 걸 볼 수 있다.
여기에 모든 정보가 다 있으므로 하나씩 살펴보자.
1) Gini 계수란?
위키백과 : ''경제적 불평등(소득 불균형)을 계수화한 것이다.''
Gini 계수는 경제에서 나온 단어지만 상관없다. 여기서 집중해서 볼 단어는 '불평등/불균형'이다.Decision Tree에서는 Gini 계수를 이용하여 데이터셋 안에 데이터가 얼마나 불평등/불균형한지 찾고 가장 좋게 균형을 이룰 수 있는 지점을 찾아 split 한다.
와닿지가 않는다. 불평등/불균형을 불순도로 바꿔서 생각해보자. 불순도라는 단어를 생각해보면, 같은 종류끼리 잘 묶여있으면 불순도가 낮고, 서로다른 종류끼리 묶여있으면 불순도는 높아진다. 분류(Classification)에서 '종류'는 target값이 될 것이다. 해당 target값을 어떠한 기준으로 split하여 2개의 노드로 나눴을때, Split된 노드들의 불순도를 낮게 만드는 요소(feature)와 부분(경계선)을 찾아야 하는것이다.
이 요소와 부분을 찾기위에 사용하는것이 바로 Gini 계수다.
2) Gini 계수를 어떻게 구할까?
Gini 계수를 이용하여 Decision Tree의 split 지점을 찾는다고 하였는데, 그럼 Gini 계수를 어떻게 구하는지 살펴보자.

Gini 계수를 구하는 공식은 간단하다.
해당 dataset에서 각 클래스별로 나올 확률의 제곱를 더하여 1을 빼주면 지니계수가 된다.
잘 생각해보면, Gini계수는 0.5를 넘지 않는다. 이유는 가장 불순도가 높을때를 생각해보면 된다.
예를들어 총 10개중 A : 5개, B: 5개가 존재하는 경우가 가장 불순도가 클것이다.
( 6:4비율이나, 4:6 비율의 불순도는 같을것이기 때문)
그렇기에 정확히 반반인 상태의 Gini계수를 구해보면.. 0.5가 나온다!
이제 마지막 단계인 Information Gain을 알아보자.
3) Information Gain이란 뭘까...?
데이터를 분류할때 Gini 계수가 얼마나 감소하는지 측정하는 양이다.
이말인 즉, IG(Information Gain)이 높을수록 불순도를 낮게 분류를 잘 해냈다는 소리가 된다.
예제를 하나 봐보자.

위 예제를 보면, IG를 구하는 방식을 알 수 있을것이다. 즉, 물려받은 데이터의 비율대로 Gini계수와 곱해 더한 후
부모 Gini계수와 뺀다는 것이다. 그럼 이게 무슨 의미가 있을까?
만약에, 부모의 Gini가 0.48이라 가정하고 IG가 0.26라고 가정한다면 어떤 의미일까?
어떤 특정 요소와 부분으로 Split한 결과, 부모의 Gini보다 IG이 더 줄었으므로 그만큼 자식 Node의 불순도는 줄어들었다고 해석할 수 있다.
그럼 만약, 부모의 Gini가 0.48, IG가 0.42라고 가정한다면?
이때는 특정 요소와 부분의 Split한 결과가 부모의 Gini와 IG가 거의 유사하므로, 자식 Node에서의 불순도 개선이 거의 이뤄지지 않았다고 해석하면 된다.
즉, Decision Tree는 IG값을 가장 크게 만드는 특정요소와 부분을 찾아 Split하는 것이다.
글이 길어졌으니.. 실제 손으로 [사진 2]의 그림을 그리는건 새로운 포스팅을 통해 해보겠다!
https://sims-solve.tistory.com/89
'머신러닝' 카테고리의 다른 글
| [ML] Extra Tree (Extremely Randomized Trees)- 정리 (0) | 2023.02.28 |
|---|---|
| [ML] Random Forest - 정리 (0) | 2023.02.28 |
| [ML] 의사결정트리(Decision Tree) - Pruning(가지치기) (0) | 2023.02.26 |
| [ML] 의사결정트리(Decision Tree) - Regression 손으로 구하기 (0) | 2023.02.25 |
| [ML] 의사결정트리(Decision Tree) - Classification 손으로 구하기 (0) | 2023.02.25 |
- Total
- Today
- Yesterday
- V11
- 초보자
- java
- docker
- 파이썬
- 딥러닝
- GIT
- 자바
- 정리
- c3k2
- YOLO
- 어탠션
- CNN
- 욜로
- 이미지
- YOLOv8
- 오류
- 오블완
- github
- GNN
- 알고리즘
- 뜯어보기
- Tree
- LLM
- 깃
- DeepLearning
- 도커
- yolov11
- 티스토리챌린지
- python
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |