
티스토리 뷰
이번 포스팅에는 직접 Decision Tree가 어떤 방식으로 분기하는지 그림으로만 보는 것이 아닌,
손으로 계산하여 정말 똑같은지 확인해보고자 한다.
만약, Decision Tree에 대해 잘 모르겠다면.. 정보를 찾아보고 오길 권한다. 밑에 링크를 참고해도 좋고...
https://sims-solve.tistory.com/88
[ML] 의사결정트리(decision tree) 정리
의사결정트리는 Forest 계열에 가장 base로 사용되는 모델이다. RandomForest , Extra Tree, 일부 Boosting계열 모델에서 n개의 decision tree가 사용되므로 의사결정 트리를 상세하고 정확하게 공부하고 넘어가
sims-solve.tistory.com
해당 포스팅은 손으로 직접 트리를 구해보는 포스팅이다.

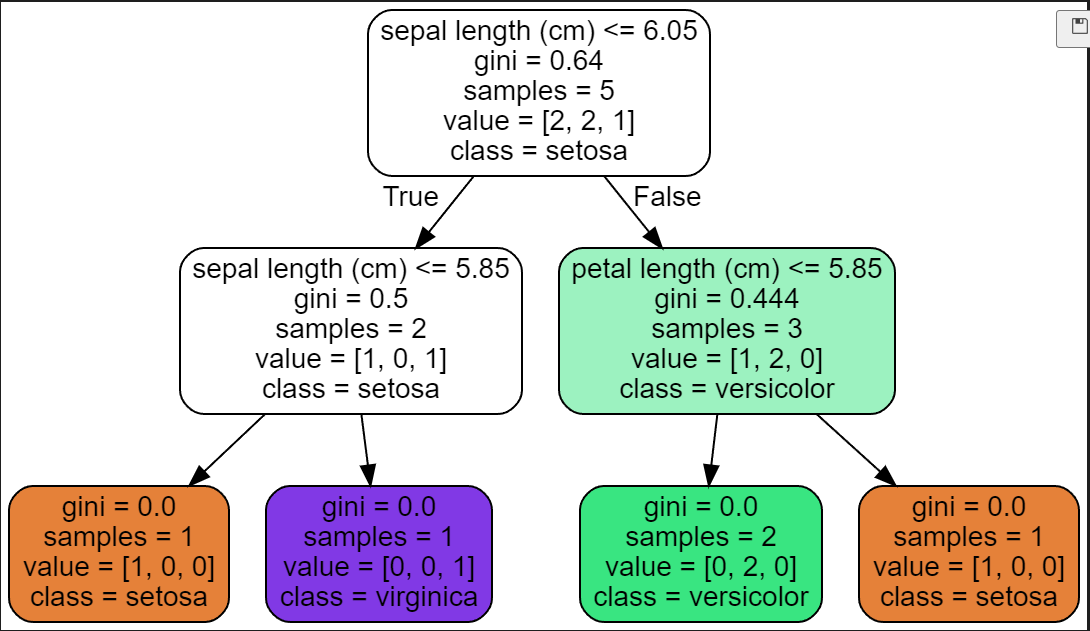
[사진 1]은 iris 데이터 중 5개만 가지고 온것이다. (모든 데이터를 하기에는 .... 힘들다...)
[사진 2]는 [사진 1] 데이터를 가지고 만든 Decision Tree를 grapviz를 통해 그린것이다!
* grapviz란? 다이어그램 형태의 그림으로 그려주는 도구
grapviz를 이용하여 .dot 파일을 만들고, 그림으로 그려줄 수 있음
그럼 직접 손으로 하나하나 계산해가면서 천천히 해보도록 하자.
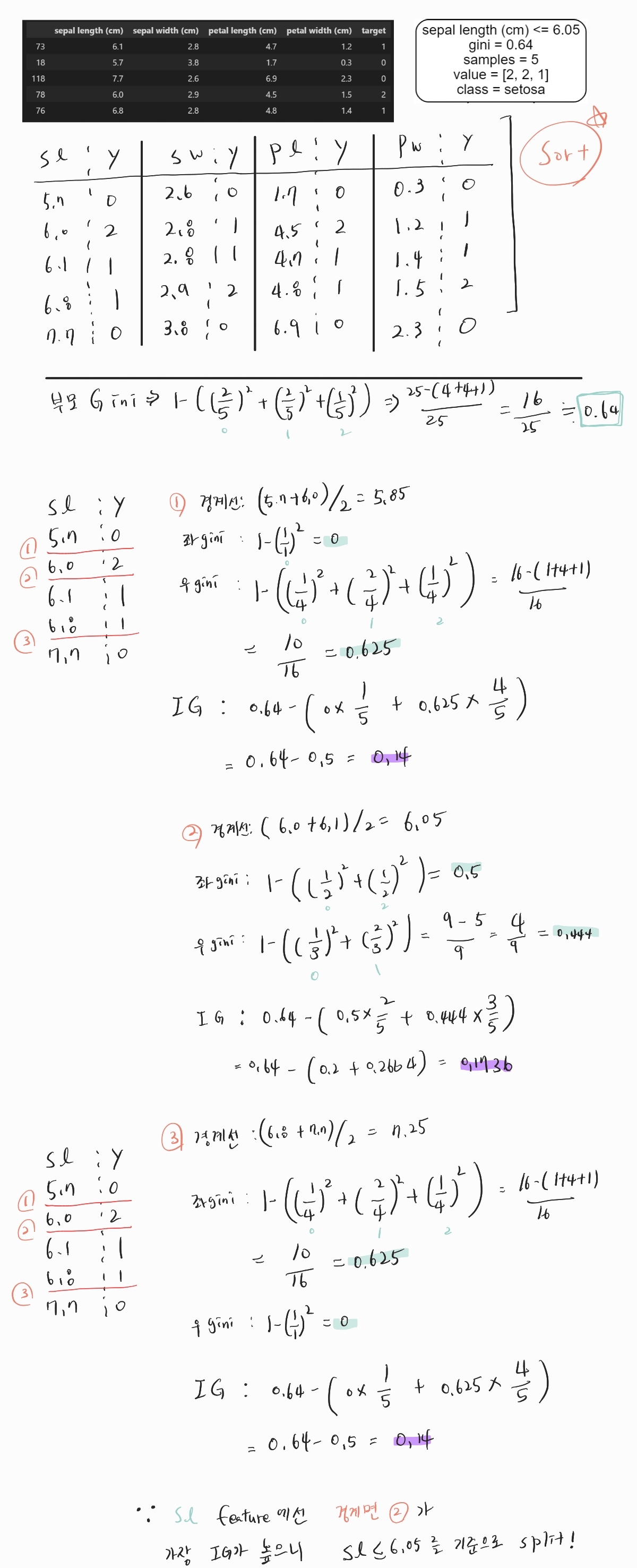
이처럼 만약, SL(Sepal Length) feature로 경계선을 찾으면 위와같이 손으로 구할 수 있다.
IG가 가장 높은 2번 경계선 6.05를 기준으로 split하면 된다고 손으로 구해보았다.
[사진 2]의 맨위 Root 노드에 써있는 정보와 비교하며 살펴보자.
1. Gini 계수가 0.64, 손으로 구한 현재 Dataset의 Gini계수도 0.64로 잘 구했다.
2. sepal length (cm) <= 6.05 , 직접 손으로 구한 경계면도 6.05로 잘 구했다!
이처럼 직접 손으로 Root노드에서 어떤 feature(요소)와 어느 경계선으로 나눌지 구할 수 있다!
근데 왜 하필 SL(Sepal Length)일까?????? 다음 사진을 보자.
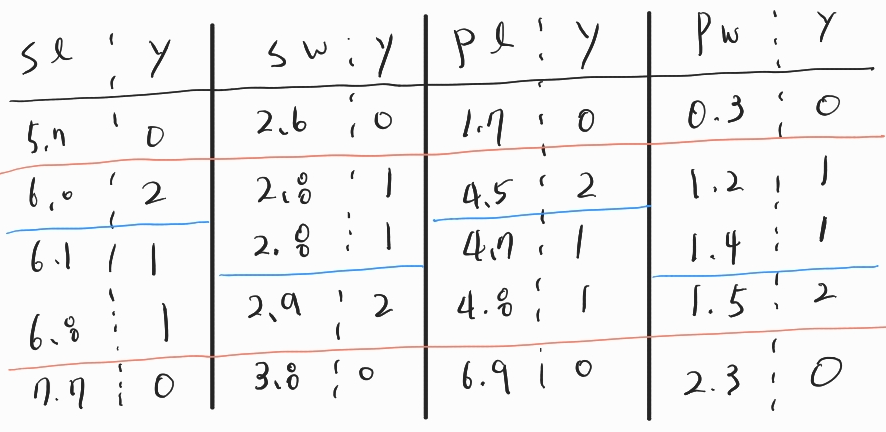
사실 해당 데이터셋 Feature들의 경계면을 면밀히 살펴보면, 모두 동일한 Gini계수를 가지게 된다.
그래서 위에서 하나의 feature만 계산했다. 즉, [사진 3] 에서의 파란색으로 표시해놓은 경계선이 모두 선택 될 수 있다.
단순히, 이 4개중 랜덤으로 하나를 선택한게 [사진 2]에서 SL이다.
다시한번 말하지만, SL , SW, PL , PW 파란색 경계면를 기준으로 Gini 계수가 동일하기에 동일한 Split 구간이 된다.
Decision Tree는 여러 feature에 같은 IG가 있으면 랜덤으로 선택하여 진행하게 된다.
정말 그럴까? 한번 봐보자.


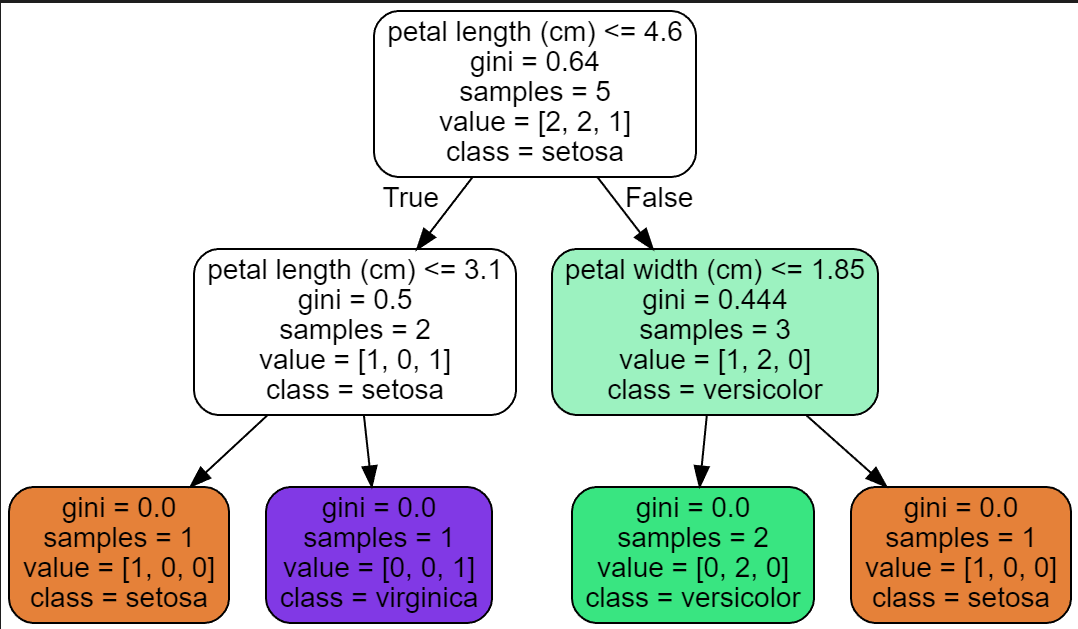

grahviz로 여러번 이미지 생성을 하면.. 위와같이 Root가 서로 다른 트리를 만들 수 있다.
SL : 6.05 / SW : 2.85 / PL : 4.6 / PW : 1.45로 [사진 3]에서의 파란색 경계선과 정확히 일치한다.
그럼 이 다음은 split된 후 자식 노드들을 손으로 다시한번 구해보자. 우측 Node먼저 구해보자.

우측 노드는 SL > 6.05이상인 데이터만 들어간다.
[사진 4]의 맨위 데이터 테이블에 파란색 v표시로 된 데이터만 사용해야한다. (총 3개)
총 3개의 데이터의 Gini계수를 구하고, 어떤 Feautre의 어떤 경계선으로 분기해야 하는지 알기위해 IG를 각각 구한다.
[사진 4]에서는 Petal length를 기준으로 나눴고, 손으로 구한 경계선 5.85와 grapviz로 그린 우측 node의 petal length (cm)가 같은 것을 확인 할 수 있다! 손으로 잘 구했다!
이 상황은 Gini = IG 이 되는 상황을 볼 수 있으며 이말은 즉, 모든 불순도가 해결됐다는 소리다!
여기서도, 왜 굳이 Petal length로 나눴을까? 각각 feature의 경계선을 그어 IG를 계산해보면 모든 값이 동일하다는 사실을 알 수 있다. (이 데이터셋을 그렇게 만들었다.. 서로 다르면 엄청나게 글이 길어지기에...)
이렇게 IG이 동일한 경우, 위에서도 말했듯이 랜덤으로 Feature를 선택하여 해당 IG이 가장 높은 경계선으로 Split을 진행한다.
한마디로, PL뿐만아니라, SL,SW,PW 모두 선택될 수 있지만, [사진 4]에서는 랜덤으로 PL이 선택된것이다.
자.. 여기까지 간단한 데이터셋으로 Decision Tree가 어떻게 트리를 구성하는지 직접 손으로 계산하고 비교하며 확인해 보았다.
필자 개인적으로는 손으로 직접 계산하고, 비교해보며 맞게 이해하고 있는지 확인해보기 위한 절차였다.
자! 지금까지 Decision Tree Classification를 직접 손으로 계산하는 작업을 진행하였다.
하지만, 우리에겐 Regression이 남아있다!!!!!!!! 다음 포스팅은 Decision Tree Regressor에 대해 또 다시 한번 손으로 직접수행해보겠다.
물론 Classification과 크게 다르지는 않다. 그래도 대부분 강의가 Classification만 진행하고 Regressor에 대한 내용이 없으니 궁금한분은 또다시 찾아와주길 바란다.
=============================== 필자의 개인적인 생각(안읽어도 됨)=================================
혹, 위에서 드는 의문이 하나 있지 않은가??
왜 feature마다 데이터를 sort 할까?????
사실 유튜브 강의에서 Decision Tree를 듣게되면, '모든 구간'를 경계선으로 보고 다 구하여 IG값이 가장 낮은 경계선을 구한다. 라고 설명이 있다.
그렇게 할 경우를 한번 생각해보자.
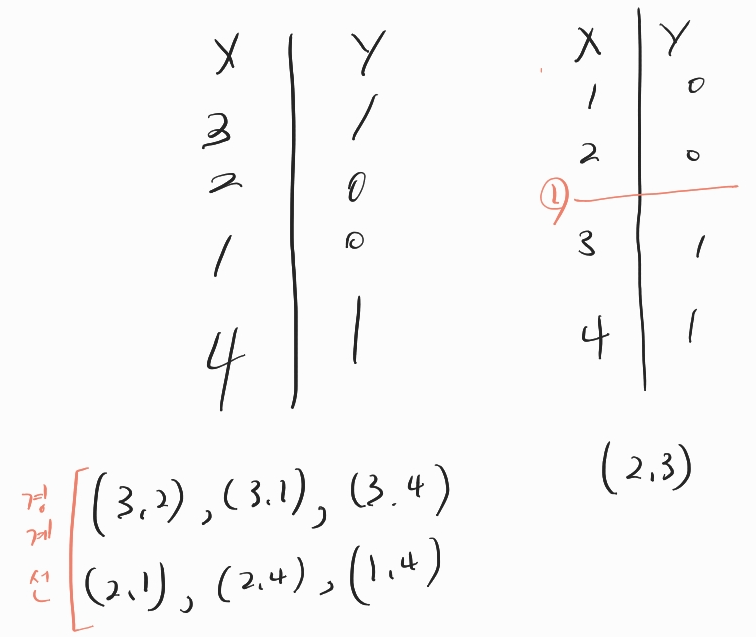
사실 이처럼 sort를 하지 않으면, 모든 값과 경계선을 비교해야 sklearn에서 나누는 경계선을 찾을 수 있을 것이다.
하지만 이는 엄청나게 비효율적이다. n^2의 복잡도를 가지고 있다.
하지만, 오른쪽처럼 sort후, Y값이 바뀌는 경계선만을 가지고 비교한다면... 왼쪽보다는 훨씬 시간복잡도가 낮을것이다.
이러한 이유때문에 sklearn에서는 데이터를 sort후 사용하는 것 같다.( 필자의 가정임 틀릴수도 있음 )
'머신러닝' 카테고리의 다른 글
| [ML] Extra Tree (Extremely Randomized Trees)- 정리 (0) | 2023.02.28 |
|---|---|
| [ML] Random Forest - 정리 (0) | 2023.02.28 |
| [ML] 의사결정트리(Decision Tree) - Pruning(가지치기) (0) | 2023.02.26 |
| [ML] 의사결정트리(Decision Tree) - Regression 손으로 구하기 (0) | 2023.02.25 |
| [ML] 의사결정트리(Decision Tree) 정리 (0) | 2023.02.25 |
- Total
- Today
- Yesterday
- 오블완
- YOLOv8
- 파이썬
- 욜로
- 딥러닝
- GNN
- V11
- 어탠션
- 이미지
- 뜯어보기
- github
- GIT
- DeepLearning
- 티스토리챌린지
- 알고리즘
- python
- yolov11
- LLM
- CNN
- 초보자
- java
- c3k2
- 오류
- 자바
- 정리
- 깃
- YOLO
- docker
- 도커
- Tree
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |