
티스토리 뷰
Decision Tree에 대한 사전지식이 필수적으로 필요합니다. Decision Tree에 대한 설명은 밑 링크를 참고하세요.
https://sims-solve.tistory.com/88
[ML] 의사결정트리(Decision Tree) 정리
의사결정트리는 Forest 계열에 가장 base로 사용되는 모델이다. RandomForest , Extra Tree, 일부 Boosting계열 모델에서 n개의 decision tree가 사용되므로 의사결정 트리를 상세하고 정확하게 공부하고 넘어가
sims-solve.tistory.com
1. Random Forest란?

간단하게 말해서 Random Forest는 이전에 살펴보았던, Decision Tree를 많이 만들어 하나의 결과를 예측하는 방식이다.
즉, 집단지성을 하겠다는 소리다..!
그럼, 단순히 Decision Tree를 N개 만들면 Random Forest일까??
당연히 바닐라 Decision Tree를 N개 생성한다면... 많은 트리의 형태가 똑같을 것이다.
왜냐, Decision Tree는 모든 'row(데이터)'와 'column(feature)'를 사용해 가장 최적의 분기점을 찾아 tree를 만든다.
그렇게 되면, 트리의 모양이 완전 똑같이 나오는 경우가 많이 생길것이다.
Random Forest는 이름에서도 볼 수 있듯, 'Random'을 통해 중복되는 Decision Tree를 만드는 것을 최대한 방지하여 앙상블(집단지성)하여 결과를 뽑아내는 방식이다.
그럼 여기서 'Random' 이란건 어디에, 어떻게 적용하는지만 살펴보면 이미 Decision Tree의 내용을 알고있기에 끝나게 된다.
그럼 자세히 살펴보도록 하자.
2. Random 어디에? 어떻게?
Random Forest는 Bagging(배깅)기법을 사용한다. 그럼 Bagging은 무엇일까?
1) Bagging- 배깅
Bagging은 Bootstrap + Aggregating을 합친 말이다. 간단하게 표현해보자.
- Bootstrap : 전체 데이터에서 무작위 복원 추출을 통해 학습 데이터 표본을 추출하는 것.
즉, Bootstrap을 사용하여 서로 다른 총 N개의 Dataset을 만들어, N개의 Decision Tree를 만들어 학습하고, 그 결과를 Aggregating, 합친다(앙상블)는 소리다.

1. 위 [그림 1]을 보자. raw dataset에는 총 5개의 data가 존재한다.
2. 이 5개 data를 복원추출(중복을 허용하여 선택)을 통해 N개의 새로운 dataset을 생성하게 된다. (Bootstrap)
3. 새로운 N개 데이터 셋을 각각 이용하여 N개의 Decision Tree를 생성한다.
(DT에 들어가는 데이터셋이 서로 다르기에 여러 모양의 Decision Tree가 생성된다.)
4. 생성된 N개의 DT를 통해 예측값을 N개만들고, Classification은 다수결(Voting), Regression은 평균(Mean)으로
최종 결과를 예측한다. (Aggregating)
Random Forest의 가장 중요한 부분은 바로 'Random'이라는 점이였다.
위 과정중 2번째 과정에서 Random의 요소가 들어간다. 복원추출로 Random하게 데이터를 뽑아 데이터 셋을 만든다.
이렇게 하는 이유는 편향과 분산을 줄일 수 있다고 한다.
그럼.. 편향과 분산은 또 뭔데.. 한번 살펴보자.
- 편향 : y^(예측값)과 y(정답)이 대체로 멀리 떨어져 있으면 결과의 편향(bias)이 높다고 표현
- 분산 : y^(예측값)이 멀리 흩어져있으면 결과의 분산(variance)이 높다고 표현
*밑에 블로그를 참조
https://opentutorials.org/module/3653/22071
Bias and Variance (편향과 분산) - 한 페이지 머신러닝
편향? 분산? 머신러닝과 무슨 상관인가 지도학습(Supervised Learning)에 대해서 이야기를 할 때는 사람이 정해준 정답이 있고, 컴퓨터가 그 정답을 잘 맞추는 방향으로 훈련(training)을 시킵니다.
opentutorials.org
왜 편향과 분산을 줄일 수 있을까?
Decision Tree를 잘 생각해보자.
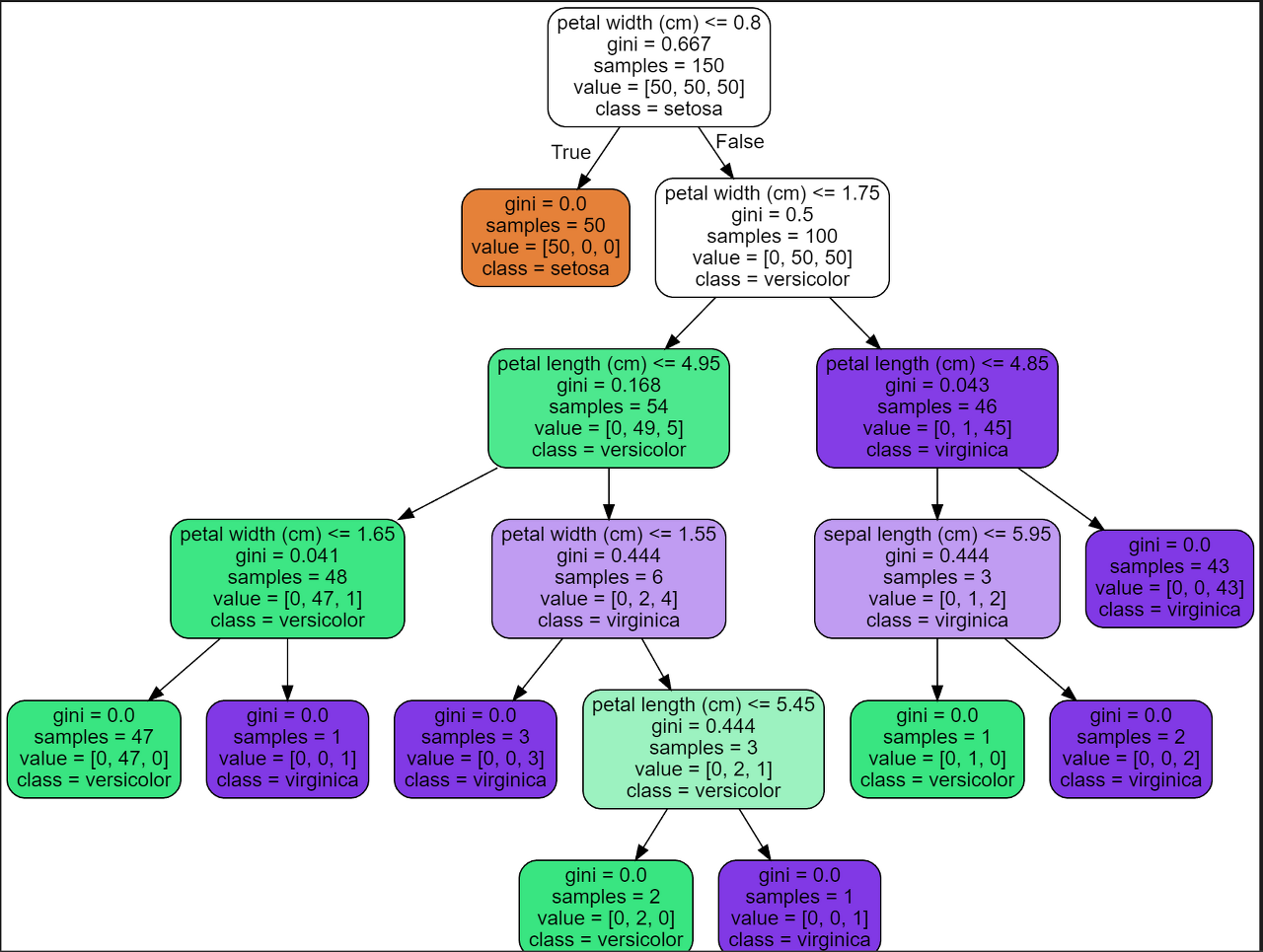
[그림 2]는 단일 Decision Tree의 모습이다.
Bias(편향)은 y^(예측값)이 y(정답)과 얼마나 떨어져 있냐를 뜻하는 것이다.
즉, DT는 depth가 많아지면 많아질 수록 Bias(편향)은 줄어들게 된다. (깊어지면 오버피팅으로 y^과 y는 유사해지니까)
분산(vriance)은 y^(예측값)이 얼마나 흩어져있냐를 뜻하는 것이다.
즉, DT에서는 depth가 많아지면, leaf node수가 기하급수적으로 많아지게 되고, 정답이 될 수 있는 범위(분류에서)가 엄청나게 세세하게 나눠져 y^간 떨어져 있다. (아닐수 있다.. 개인적인 생각)
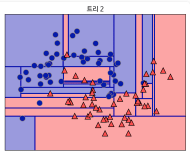
마치 [그림 3]처럼 정답을 결정하는 구간이 엄청나게 세세하게 나눠져 y^이 이곳저곳 떨어지게 된다.
여기서, Bootstrap으로 복원 추출한 dataset를 사용한다면, [사용된 데이터, 사용되지 않는 데이터]로 나눠질텐데
raw data 전체를 학습시키는 것보다 사용되지 않은 데이터가 존재하니 분산을 줄일 수 있다.
(천천히 생각해보자, raw dataset과 복원 추출한 dataset의 총 갯수는 같지만, unique한 데이터 갯수는 차이가 난다.
raw dataset 의 unique한 데이터 갯수는 항상 복원 추출한 dataset unique 보다 크거나 같기( >= ) 때문에 복원 추출한 dataset으로 DT를 생성하면 분산은 줄게된다.)
게다가 DT를 N개 만들어 다수결, 평균을 내어(앙상블) 분산을 더욱 줄일 수 있게 되는 것이다.
이러한 이유로 Bagging기법을 사용하여 Random Forest를 학습한다.
추가적으로, 복원추출에서 Random성을 주었지만, Feature를 선택하는 것에도 Random성을 주게 된다.
Random Forest의 내부 코드를 살펴보면 'max_features'를 sqrt(Feature 갯수)로 취하는 것을 볼 수 있다.
(regression은 모든 Feature 고려 , Bagging만 진행)

위 코드처럼 classification일때는 sqrt를 취해 1개의 DT에서 split을 할때 몇개의 feature를 고려하여 best 부분에서 split을 진행한다. ( N개의 feature에서 가장 best split 구간을 찾고, 그 split 구간을 사용)

위 [그림 3]은 iris data를 Random Forest로 구분한 것이다. iris data는 총 4개의 feature가 있다.
[ sepal length (cm), sepal width (cm), petal length (cm), petal width (cm) ]
위 그림에서 feature 4개가 모두 split에 사용 된 것을 볼 수 있다.
이말인 즉, split할때 총 2개의 feature를 랜덤으로 선택하여 best로 split하는 구간을 선택하고 모든 분류가 될때까지 진행하게 된다.
( 주의하자, 총 2개의 feature를 처음부터 고정시켜놓고 학습을 진행하는 것이 아닌, split 하기위한 feature 선택을 항상 랜덤으로 선택하여 진행하게 된다.)
복원추출 + Feature 두 부분에서 Random성을 주고 수많은 DT를 만들어 앙상블하는 방식이 Random Forest다!
이렇게 된다면, 모든 데이터+ 피쳐를 사용한 DT보다 장점이 존재한다.
1. 과적합 방지
2. 앙상블로 인한 성능개선
( https://mlu-explain.github.io/random-forest/ 해당 사이트에서, 각 DT의 성능에 따라 앙상블 했을때 RF의 성능을 볼 수 있다)
하지만 N개의 DT를 만들어야 하기에 시간이 오래걸린다는 단점이 존재하긴 한다.
그럼, 이제 sklearn에서 제공하는 RandomForest의 파라미터를 한번 살펴보자.
n_estimators : 몇개의 DT로 RandomForest를 구성할 것인가?
bootstrap : 복원추출을 사용할 것인가?
oob_score : 복원 추출시 선택되지 않은 data를 가지고 일반화 점수를 얻을것인가?
n_jobs : 병렬 처리할 작업 수
random_state : 재현성을 위한 random 고정
verbose : 진행상황 출력
warm_start : ? ( 와닿지 않음)
max_samples : 최대 샘플 수
criterion
max_depth
min_samples_split
min_samples_leaf
min_weight_fraction_leaf
max_features
max_leaf_nodes
min_impurity_decrease
class_weight
ccp_alpha
노란색으로 표시된 것은 DT에 없는 파라미터이기에 노란색 표시한 것만 설명을 적어놓았다.
여기까지 Random Forest에 대해 살펴보았다. DT의 내용을 알고있으면 Random성만 고려하면 되니 쉽게 이해할 수 있을 것이다.
이 다음에는 마지막으로 ET(Extra Tree)를 살펴보겠다.
================================ 추가 설명 ??? ================================
사실 코드적으로 봤을때, 복원추출을 한다고 하면 새로운 데이터 셋을 만들것인데 디버깅을 통해 복원 추출된 데이터셋이 어떻게 구성되었는지 볼 수 없을까?라는 의문에서 시작하여 디버깅을 해봤다.
sample_weight라는 변수를 통해 어떤 데이터가 몇 번 사용될 것인지 정보를 담고있는 모습을 확인하였다.

이처럼 , 2번째 데이터는 한번도 들어가지 않고, 3번째 데이터는 2개가 들어간다는 표현을 sample_weight를 통하여 알려줘 학습을 진행한다!
'머신러닝' 카테고리의 다른 글
| [ML] Decision Tree vs Random Forest vs Extra Tree 표 비교 (0) | 2023.02.28 |
|---|---|
| [ML] Extra Tree (Extremely Randomized Trees)- 정리 (0) | 2023.02.28 |
| [ML] 의사결정트리(Decision Tree) - Pruning(가지치기) (0) | 2023.02.26 |
| [ML] 의사결정트리(Decision Tree) - Regression 손으로 구하기 (0) | 2023.02.25 |
| [ML] 의사결정트리(Decision Tree) - Classification 손으로 구하기 (0) | 2023.02.25 |
- Total
- Today
- Yesterday
- yolov11
- python
- docker
- 깃
- V11
- 이미지
- 도커
- CNN
- java
- LLM
- 딥러닝
- 티스토리챌린지
- 정리
- YOLOv8
- 뜯어보기
- 초보자
- 오블완
- 자바
- github
- YOLO
- GNN
- DeepLearning
- 욜로
- 알고리즘
- 오류
- GIT
- Tree
- 파이썬
- c3k2
- 어탠션
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |